搜索过程
搜索过程大致包括如下步骤:
- 用户输入查询语句。
- 对查询语句进行语法分析和语言分析,得到一系列词(Term)。
- 通过语法分析得到一个查询树。
- 利用查询树搜索索引,从而得到每个词的文档链表,对文档链表进行交、差操作,并得到结果文档。
- 将搜索到的结果文档按查询的相关性进行排序。
- 返回查询结果给用户。
查询
布尔查询
布尔查询有以下两个特点:
- 子查询可以以任意顺序出现。
-
查询语句中可以嵌套多个查询条件,其中包括布尔查询。布尔查询包含以下4种操作符,并且它们均是一种数组,数组中是对应的判断条件。
must:必须匹配 (返回结果中评分字段的结果有意义)。must_not:过滤子句,必须不能匹配 (返回结果中评分字段的结果无意义)。should: 选择性匹配,至少满足一条 (返回结果中评分字段的结果有意义)。filter: 过滤子句,必须匹配 (返回结果中评分字段的结果无意义)。
查询上下文
查询上下文中使用的查询子句需要解决的问题是“此文档与此查询子句的匹配程度如何?”,除了决定文档是否匹配之外,查询子句还计算一个分数_score,表示文档相对于其他文档的匹配程度。
GET /test-tracing-span-*/_search
{
"_source": [ "project_name", "module_name", "api_name", "component" ],
"query": {
"terms": { "component": ["grpc", "gateway", "http"] }
},
"size": 10
}
过滤上下文
在过滤上下文中,查询子句解决的问题是 “此文档是否与此查询子句匹配?”,答案是简单的“是”或“否”,不计算分数。过滤上下文主要用于过滤结构化数据。
GET /test-tracing-span-*/_search
{
"_source": [ "project_name", "module_name", "api_name", "component" ],
"query": {
"bool": {
"filter": [ { "terms": { "component": ["grpc", "gateway", "http"] } } ]
}
},
"size": 10
}
must vs. filter
GET /test-tracing-span-*/_search
{
"query": {
"bool": {
"must": [
{ "match": { "project_name": "shopeepaybase" } },
{ "match": { "channel": "11" } }
],
"filter": [
{ "term": { "component": "grpc" }},
{ "range": { "log_timestamp": { "gte": 1677081654512 } } }
]
}
},
"size": 20
}
post_filter
GET /shirts/_search
{
"query": {
"bool": {
"filter": { "term": { "brand": "gucci" } }
}
},
"aggs": {
"colors": {
"terms": { "field": "color" }
},
"color_red": {
"filter": { "term": { "color": "red" } },
"aggs": {
"models": {
"terms": { "field": "model" }
}
}
}
},
"post_filter": { "term": { "color": "red" } }
}
全文检索
全文检索功能用来搜索分析过的文本字段,如电子邮件正文。一般情况下索引和查询的分析器应该相同,但也可以根据需求设置不同的分析器。
match
match 查询接受文本、数字或日期等多种类型,分析它们,并构造查询。
匹配查询的类型为boolean。这意味着对所提供的文本进行分析,分析过程从所提供的文本构造一个布尔查询。
match_phrase
query_string
聚合
聚合是一种基于搜索的数据汇总,通过组合可以完成复杂的操作。聚合可以对文档中的数据进行统计汇总、分组等,对一个聚合进行操作可以看作在一组文档中分析数据。
聚合的分类
- 度量聚合——在一组文档中对某一个数字型字段进行计算得出指标值。
- 分组聚合——创建多个分组,每个分组都关联一个关键字和相关文档标准。当聚合执行的时候,所有的分组会根据自身标准评估每一个符合的文档。当文档匹配分组标准的时候,会将文档划分进相关的分组里。聚合进行完成时,会给出一个分组列表,每一个分组都会有一组“属于”它的文档。
- 管道聚合——这一类聚合的数据源是其他聚合的输出,然后进行相关指标的计算。
除此之外,还可以在分组聚合的基础上添加聚合并执行,这就是聚合的嵌套,通过嵌套可以完成很多复杂的聚合操作!
查询示例
简单查询
# 查询userinfo索引库中所有的文档数据
GET /userinfo/_search
{
"query": { "match_all": {} }
}
# 查询userinfo索引库中所有的文档数据,根据age字段进行倒序输出
GET /userinfo/_searc
{
"query": { "match_all": {} },
"sort": [
{ "age": { "order": "desc" } }
]
}
# 多字段排序
GET /索引名称/_search
{
"query": { "match_all": {} },
"sort": [
{ "field1": { "order": "desc" } },
{ "field2": { "order": "asc" } }
]
}
聚合查询
GET /test-tracing-span-*/_search
{
"size": 0,
"aggs": {
"avg_cost": {
"avg": { "field": "latency" }
}
}
}
GET /test-tracing-span-*/_search
{
"size": 0,
"aggs": {
"avg_cost": {
"avg": { "script": { "source": "doc.latency" } }
}
}
}
GET /test-tracing-span-*/_search
{
"size": 0,
"aggs": {
"avg_cost": {
"avg": { "field": "extra_info.timecost" }
}
}
}
// 返回按region分组的数量
GET /test-tracing-span-*/_search
{
"size": 0,
"aggs" : {
"region_count" : {
"terms" : { "field" : "region_name" }
}
}
}
// 返回去重后的region数量
GET /test-tracing-span-*/_search
{
"size": 0,
"aggs" : {
"region_count" : {
"cardinality" : { "field" : "region_name" }
}
}
}
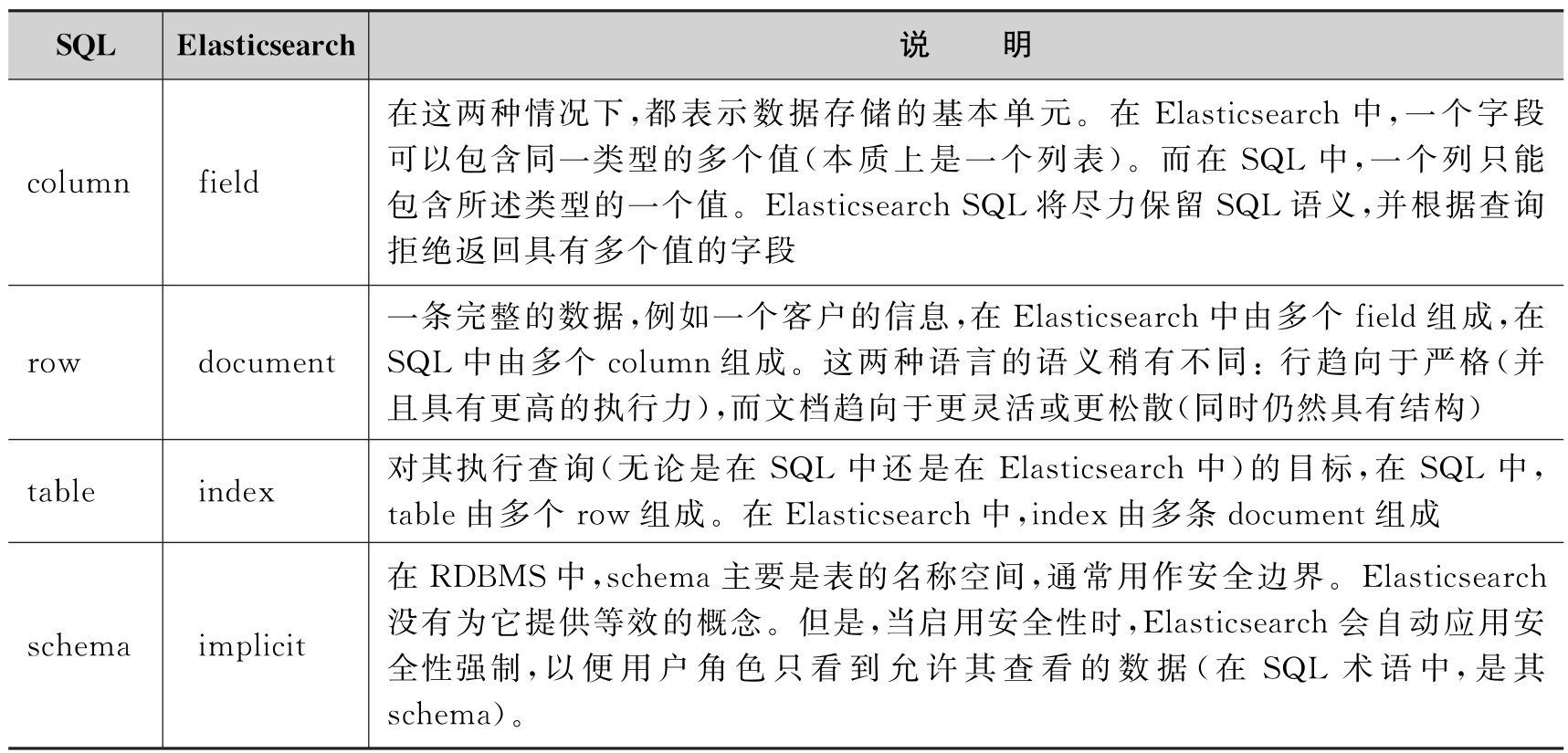
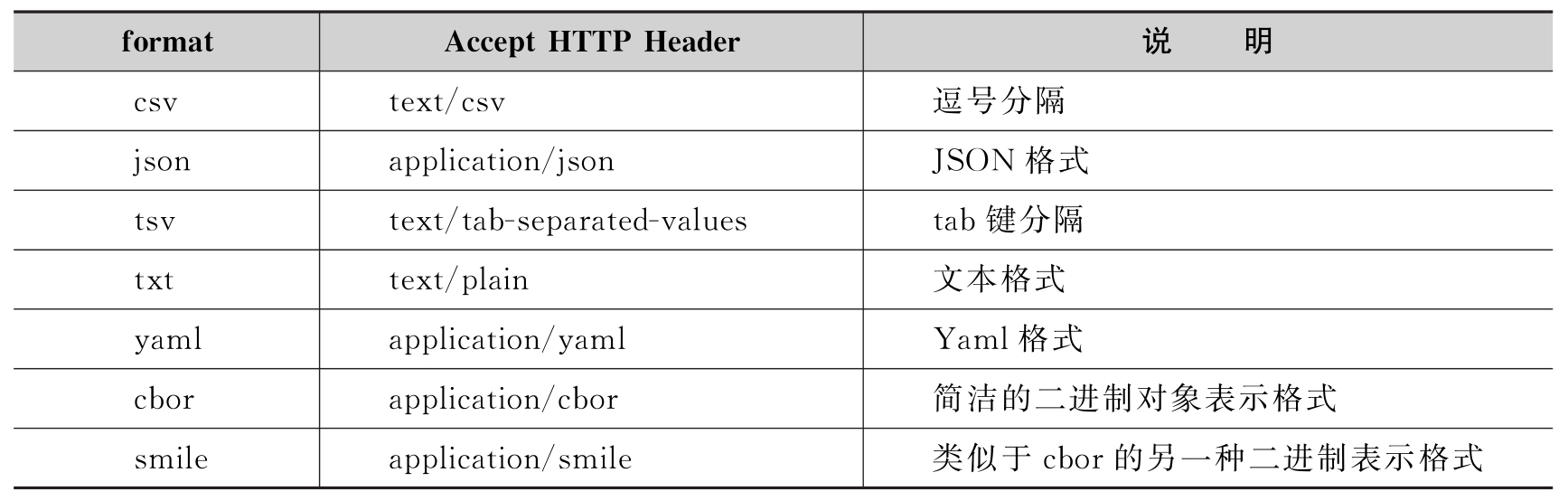
SQL
DSL vs. SQL
GET _xpack/sql?format=txt
{
"query":"DESCRIBE \"live-tracing_api_in_hour_2023013101\""
}
column | type | mapping
-------------------+---------------+---------------
api_name |VARCHAR |keyword
avg_client_latency |BIGINT |long
avg_latency |BIGINT |long
component |VARCHAR |keyword
env_name |VARCHAR |keyword
error_count |BIGINT |long
grass_hour |VARCHAR |keyword
idc_name |VARCHAR |keyword
max_client_latency |BIGINT |long
max_latency |BIGINT |long
min_client_latency |BIGINT |long
min_latency |BIGINT |long
region_name |VARCHAR |keyword
request_count |BIGINT |long
source_api_name |VARCHAR |keyword
source_idc_name |VARCHAR |keyword
source_module_name |VARCHAR |keyword
source_project_name|VARCHAR |keyword
source_region_name |VARCHAR |keyword
source_service_name|VARCHAR |keyword
target_module_name |VARCHAR |keyword
target_project_name|VARCHAR |keyword
target_service_name|VARCHAR |keyword
timestamp_end |TIMESTAMP |datetime
timestamp_start |TIMESTAMP |datetime
POST /_sql?format=txt
{
"query": "SELECT * FROM \"test-tracing_api_in_hour_*\" ORDER BY max_latency DESC LIMIT 5"
}
POST /_sql/translate
{
"query": "SELECT COUNT(DISTINCT api_name) FROM \"test-tracing-span-*\" GROUP BY project_name, module_name"
}
{
"size" : 0,
"aggregations" : {
"groupby" : {
"composite" : {
"size" : 1000,
"sources" : [
{ "group_by_project_name" : { "terms" : { "field" : "project_name", "missing_bucket" : true, "order" : "asc" } } },
{"group_by_module_name" : { "terms" : { "field" : "module_name", "missing_bucket" : true, "order" : "asc" } } }
]
},
"aggregations" : {
"api_count" : { "cardinality" : { "field" : "api_name" }
}
}
}
}
}
POST /_sql/translate
{
"query": "SELECT COUNT(DISTINCT api_name) as api_count FROM \"test-tracing-span-*\" WHERE component IN ('grpc', 'http', 'gateway') GROUP BY service_name ORDER BY api_count desc"
}
{
"size" : 0,
"query" : {
"terms" : { "component" : ["grpc", "http", "gateway"],
"boost" : 1.0
}
},
"_source" : false,
"stored_fields" : "_none_",
"aggregations" : {
"groupby" : {
"composite" : {
"size" : 1000,
"sources" : [
{ "25bcc19b" : { "terms" : { "field": "service_name", "missing_bucket": true, "order": "asc" } } }
]
},
"aggregations" : {
"ac653b38" : { "cardinality" : { "field" : "api_name" } }
}
}
}
}