微服务架构的组件
在正式学习如何搭建微服务架构之前,我们先来了解一下微服务架构中涉及的一些常见组件名称及其作用。
- 服务注册中心:注册系统中所有服务的地方。
- 服务注册:服务提供方将自己调用地址注册到服务注册中心,让服务调用方能够方便地找到自己。
- 服务发现:服务调用方从服务注册中心找到自己需要调用服务的地址。
- 负载均衡:服务提供方一般以多实例的形式提供服务,使用负载均衡能够让服务调用方连接到合适的服务节点。
- 服务容错:通过断路器(也称熔断器)等一系列的服务保护机制,保证服务调用者在调用异常服务时快速地返回结果,避免大量的同步等待。
- 服务网关:也称为API网关,是服务调用的唯一入口,可以在这个组件中实现用户鉴权、动态路由、灰度发布、负载限流等功能。
- 分布式配置中心: 将本地化的配置信息(properties、yml、yaml等)注册到配置中心,实现程序包在开发、测试、生产环境的无差别性,方便程序包的迁移。
除此之外,读者在学习时,可能还会在一些参考资料中看到服务的健康检查、日志处理等组件内容。 由于使用上面所描述的组件即可实现微服务架构的快速入门,所以本书中并未对这些额外的组件进行讲解,有兴趣的读者可自行学习。
断路器——Hystrix
Netflix微服务从外而内分层视图架构
Netflix是业界微服务的楷模,有大规模生产级微服务的成功实践,其分层视图如图12-1所示。
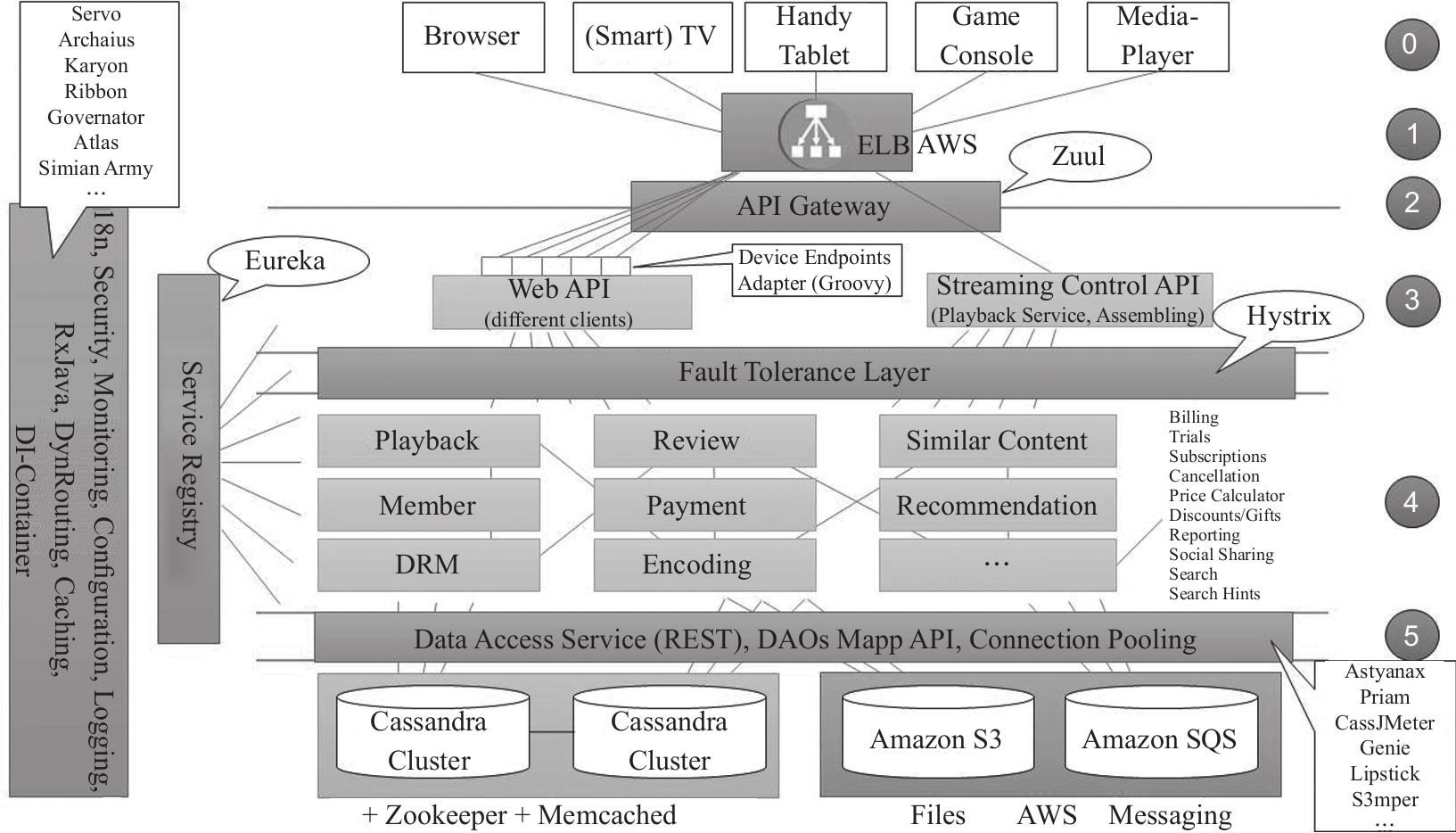
- 第0层:端用户设备层,支持浏览器、手持设备、智能电视、游戏设备等。据称Netflix可支持超过1000种端用户设备。
- 第1层:接入层,基于AWS的ELB接入用户流量。
- 第2层:网关层,将外部请求反向路由到内部微服务,Netflix使用自研Zuul网关。网关只负责跨横切面功能(反向路由、安全、限流熔断和日志监控等),无业务逻辑。网关无状态部署,依赖前端ELB做负载均衡。
- 第3层:聚合服务层,负责对后台微服务进行聚合、裁减、加工后暴露给前端设备,在Netflix的体系中,该层也称边界服务层(EdgeService)或者设备适配层。考虑到设备的多样性和前端业务的多变性,Netflix前端团队大量使用Groovy脚本作为聚合层的主要开发语言,同时兼容Java又具有脚本易于变更特性。
- 第4层:后台基础服务层,提供支持Netflix业务的核心领域服务(Playback、Member、Review、Payment等),在Netflix体系中,该层也称为中间层服务层(Middle Tier Service)。
- 第5层:数据访问层,提供对Cassandra NoSql数据存储(Netflix的主要数据持久化方式),后台服务(Memcached、Zookeeper、S3、SQS等)和大数据等的访问和工具支持。
https://resources.sei.cmu.edu/asset_files/Presentation/2016_017_001_454646.pdf
SpringBoot微服务的安全与防护
SpringBoot微服务开发上线的主要目的是对外服务,所以,安全起见,每一个SpringBoot微服务都需要鉴别哪些访问者是合法的,这就需要一个服务访问的认证和鉴权的过程(Authentication And Authorization),有了服务访问者的身份认证信息,我们的SpringBoot微服务才能够对其进行审计,进行访问限流,甚至直接拉到黑名单,所以,对SpringBoot微服务访问前端的安全防护是基本要求。
另外,虽然内网是相对安全的,但不排除某些人通过未知漏洞渗透到内网,然后嗅探内网通信获取敏感信息等情况发生,所以,对于微服务的访问者与提供方之间的通信信道,也可以进行适当加密。
当然,相对于SpringBoot微服务的后端管理接口的安全防护来说,SpringBoot微服务访问的前端防护以及信道加密可以相对弱化一些,毕竟,SpringBoot微服务存在的本身就是对外提供服务访问,况且还是相对安全的内网,但SpringBoot微服务的后端管理接口则不然,它们一旦被利用甚至滥用,造成的影响可就无法估量了。
云数据库
云数据库的特征可以概括为解放用户和适应业务两类。具体可以转化为如下6条内容,其中前3条属于解放用户的范畴,后3条属于适应业务的范畴。
- 智能运维(智能数据库):故障可自愈,包括宕机自动迁移、故障隔离、异常流量自动调度、负载均衡、自动限流降级等。数据库可自动调优,自动调节资源的使用,拥有自适应算法以应对应用的负载等。这样的能力可以概括为自调优、自适应、自动驾驶(工业界将自动驾驶的标准分为6个级别,数据库界借用了此级别来定义数据库自动驾驶的概念)。
- 易于管理:智能运维的表现就是易于管理。云数据库具备自动化异常分析诊断能力,可在运维操作中实现白屏化、智能化、规模化、少人化。
- 极致体验:用户对于数据库的申请、创建、监控、报警、故障定位都可以最简单的方式完成,给用户以极致便捷的体验。
- 弹性伸缩:能够根据业务的应用负载自动伸缩,具备秒级扩缩容能力,可灵活动态分配或释放资源,结合弹性计费策略,可以大幅度降低用户的使用成本。这一条中部分内容和智能运维重合,但描述问题的角度不同,本条是从系统可扩展性的角度,对云数据库的重要特征进行描述。业务或系统上云,是购买了一种应对未来的可能。对于正处于业务发展中的商户而言,随着数据的积累在云端可随时扩展存储,也可自由扩展计算节点,这样对于一个从小向大发展的商户而言,是一种最佳的资源利用方式,也是一种成本最低的方式。而支持这种业务发展的技术,就是弹性伸缩。在弹性伸缩中需要考虑事务执行的先后次序,这个次序对于数据库架构而言,就是存算分离。
- 按需计费:支持按量(如流量、存储量、调用次数、调用时长、核数、内存资源占用量等)制定多种定价策略,使用户可根据业务情况灵活匹配出最优计量模式,节约用户成本。
- 安全、资源隔离:云数据库采用共享池化技术来提高计算、存储、网络等资源的利用率,隔离用户对资源的并发争用;另外提供多租户方式以做到安全隔离,避免信息泄露或遭受攻击等。
上述内容为云数据库的设计指出了方向。
Thread模拟营业大厅叫号机程序
相信很多人都去过银行、医院、移动营业厅、公积金中心等,在这些机构的营业大厅都有排队等号的机制,这种机制的主要作用就是限流,减轻业务受理人员的压力。当你走进营业大厅后,需要先领取一张流水号纸票,然后拿着纸票坐在休息区等待你的号码显示在业务办理的橱窗显示器上面
微服务部署分为以下 3个阶段
- 微服务 1.0: 仅使用服务注册和发现,基于 Spring Cloud或 Dubbo进行开发。
- 微服务 2.0: 使用了熔断、限流、降级等服务治理策略,并配备完整的服务工具和平台。
- 微服务 3.0: Service Mesh 将服务治理作为通用组件,下沉到平台层实现,应用层仅关注业务逻辑,平台层可以根据业务监控自动调度和参数调整,实现 IT 智能化运维(Artifical Intelligence for IT Operations,AIOps),意指将人工智能的能力与运维相结合,通过机器学习的方法来提升运维效率)和智能调度。 容器和微服务可用于支持 PaaS平台的能力开放,实现云服务的增值。容器和微服务有效支持持续集成与持续交付,加速业务上线。
目前使用得最多的开源微服务框架是 Spring Cloud。Spring Cloud是一系列框架的有序集合,它利用 Spring Boot的开发便利性简化了分布式系统基础设施的开发,如服务发现注册、配置中心、消息总线、负载均衡、断路器、数据监控等,都可以用 Spring Boot实现一键启动和部署。
服务集成
这里的服务即Web服务,它提供了一项不依赖于语言,不依赖于平台,可以实现用不同语言编写的应用程序相互通信的技术。Web服务使用基于XML的协议来描述要执行的操作或者要与另一个Web服务交换的数据。
在企业应用集成体系中,服务集成是一项用来实现流程集成和数据集成的技术,通过标准化的XML消息传递操作,实现跨系统、跨平台的应用交互和数据共享。
服务集成目前有两种主流框架:一种是比较传统的面向服务的架构(SOA),另一种是微服务架构。
- SOA: SOA是一个组件模型,它将应用程序的不同功能单元(称为服务)进行拆分,并通过这些服务之间定义良好的接口和协议联系起来,为企业提供灵活、便捷的应用集成。SOA强调了服务的组合和重用,以更快地满足业务需求。企业服务总线(ESB)是SOA体系中的核心成员,主要提供服务注册、服务编排、服务发布、消息路由、消息解析、消息验证等功能。
- 微服务架构: 微服务架构(Microservice Architecture)是一种架构概念,旨在通过将功能分解到各个离散的服务中来实现对解决方案的解耦。与SOA类似,微服务架构的核心思想是将应用系统的共性功能抽象出来,形成可以独立运行的服务。微服务架构中的核心组件是微服务网关(API Gateway),微服务网关主要提供微服务的发现、注册、监控、熔断、限流、服务降级、安全控制等功能。
服务容错
对分布式环境中的服务而言,服务自身会失败的同时还会因为依赖其他服务而导致失败。除了常见的超时、重试和异步解耦等手段,还需要考虑针对各种场景的容错机制,服务容错技术包括以下常见机制和策略。
- 集群容错策略
- 服务隔离机制
- 服务限流机制
- 服务熔断机制
业界存在一批与服务容错相关的技术组件,包括 以失效转移 Failover 为代表的集群容错策略, 以线程隔离、进程隔离为代表的服务隔离机制, 以滑动窗口、令牌桶算法为代表的服务限流机制, 以及服务熔断机制。 而从技术实现方式上看,在Spring Cloud中,这些机制一部分包含在接下来要介绍的服务网关中,另一部分则被提炼成单独的开发框架,如专门用于实现服务熔断的Spring Cloud CircuitBreaker组件。
消息中间件
消息中间件(MQ)是指支持与保障分布式应用程序之间同步或异步收发消息的中间件。它可以解决一些高并发的性能瓶颈,将消息队列中的任务分发给消息消费者。
MQ具有异步、吞吐量大、延时低的特性,适合执行投递异步通知、限流及削峰平谷等任务。利用一些特性,可以做定时任务。
消息中间件的可选性很多,如RabbitMQ、RocketMQ及ZeroMQ。
云计算的挑战及解决方法
云计算在给我们带来巨大方便的同时,也因为其新特性给研发带来了相当大的挑战。在我看来,云计算带来的最大挑战在于,为了充分使用云的弹性伸缩能力,我们必须实现分布式的软件架构,以支持其水平扩展。
这种分布式的架构和传统的单体架构区别很大。如果处理不好,会给产品的稳定性和可维护性带来很大负面作用。 其中最典型的例子当属微服务。微服务架构非常适合云计算,如果使用得当,可以充分利用云计算的弹性伸缩能力。但如果使用不当、管理不好的话,就会出现调用混乱、依赖不清晰、难以维护等问题。
以我的经验看来,应对分布式计算带来的挑战,首先要把集中管理和团队自治进行有机结合,其次要做到高效的错误处理。
方法一:集中管理和团队自治相结合
要做好分布式计算,首先要让解耦的产品团队能够独立进行产品的设计、开发、测试和上线,这样才能真正利用解耦带来的灵活性。但同时必须要有一定的集中式管理,这样才能把控全局。集中管理和团队自治,两者相辅相成,缺一不可。然而重视后者而忽略前者,是分布式开发模式中一个非常常见的错误。
加强集中管理的最重要手段是信息可视化,具体分析如下。
- 提供整体系统的质量看板,让大家可以一眼看到整个系统中各部分的运行状况,从而快速寻找瓶颈、定位问题。
- 建设微服务调用链追踪系统,收集每一个客户服务请求从收到请求到返回结果的全流程日志,包括过程中的所有组件、微服务、请求处理时长、日志细节等信息,以帮助开发人员解决由调用链复杂而导致的调测困难问题。
方法二:高效的错误处理
在分布式系统中,很多组件同时运行,必然会有很多局部错误(即独立的组件错误)发生。我们必须要对这些局部错误进行恰当而及时的处理,确保局部错误不会对全局带来太大负面影响。具体来说,可以使用的方法包括如下几种。
- 信息可视化。通过数据可视化、监控、预警,迅速发现错误以便及时处理。
- 错误隔离。把错误控制在一定范围内。比如,微服务的一大好处就是可以把错误限制在单独的服务中。
- 提高系统容错性。确保一个服务的问题不会影响其他服务,形成所谓的“雪崩效应”。具体办法包括限流、熔断机制等。
- 自动修复。能够自动探测到问题并采取修复措施。其中最常见的一个办法是重启服务,对无状态服务非常有效。
Redis应用场景
Redis在日常开发中使用场景还是挺多的,大致在以下场景会更适合使用Redis:
- 热点数据缓存。Redis访问数据比数据库快几个数量级,因此针对热点数据可以实现缓存,保障访问速度。
- 限时业务。比如手机验证码60秒只能发一条的场景。
- 计数器场景。Redis的原子递增命令可以用于高并发的秒杀活动、接口限流等等。
- 排行榜和投票场景。借助Redis的zset实现点赞数据实时排行,而数据库实现的效率非常之低。
- 分布式锁。分布式锁一般用在分布式系统中以防止出现高并发导致的数据混乱问题。
- 消息订阅模式。比如推送系统,推送系统的发布者往Redis写消息,而消费者监听Redis消息完成实际的消息推送。
Spring Cloud微服务架构
- 微服务网关(Zuul、Gateway)是微服务对外发布的出口,同时也是外部流量的入口。通过网关可以统一外部的入口、屏蔽后台的细节,同时也可以在网关中做统一的处理(如鉴权、限流等)。网关就类似一栋大厦一楼的大堂,所有进出大厦的人必须从大堂经过。Zuul是Spring Cloud提供的最高的网关组件,其本质就是一个Web Servlet应用,提供动态路由、监控、弹性和安全等边缘服务的框架。SpringCloud Gateway也是网关组件,是后来出现的网关组件,目标是替换Zuul,旨在为微服务架构提供一种简单而有效的统一API路由管理方式,它不仅提供统一的路由方式,并且基于Filter链的方式提供了网关的基本功能,如安全、监控/埋点和限流等。
- 熔断器(Hystrix)即容错管理工具,旨在通过熔断机制控制服务和第三方库的节点,从而对延迟和故障提供更强大的容错能力。它类似于保险丝的功能,当线路的负载过高时保险丝会自动熔断从而保护线路,避免因线路过载导致线路烧毁、起火等事故。
云原生最佳实践
集成
集成是配合分解完成的动作。分解完成的各个组件或子系统,通过合适的接口设计,最终还能够集成为一个完整的整体。分解的目的仅仅是加速开发和降低问题的复杂度,如果分解后的内容无法集成在一起,分解就没有任何意义。我们可以将“分解+集成”理解为架构的核心思考方式和方法。
常见的集成方式
在SOA体系下,服务之间通过ESB通信,许多业务逻辑存在于中间层(消息的路由、转换和组织)。
微服务架构倾向于减少中心消息总线(类似于ESB)的依赖,将业务逻辑分布在每个具体的服务终端。大部分微服务基于 HTTP、JSON这样的标准协议,集成不同的标准和格式变得不再重要;并且,在微服务架构中还可以采用轻量级的消息总线或者网关,有路由功能,没有复杂的业务逻辑。 下面介绍几种常见的集成方式。
点对点方式
在点对点方式中,服务之间直接调用。每个微服务都开放Rest API,并且调用其他微服务的接口。
将这种方式应用于简单的微服务架构是完全可行的,但是当微服务架构越来越复杂时,这种方式就不适用了。这有些类似于 SOA 的ESB,所以我们尽量不采用点对点的集成方式。
API网关方式
API网关方式的核心要点是,所有客户端和消费端都通过统一的API网关接入微服务,在API网关层处理所有的非业务功能。通常,API网关也提供 Rest、HTTP的访问API,服务端通过API-GW注册和管理服务。
举个例子,在某个项目中,所有业务接口都通过API网关暴露,是所有客户端接口的唯一入口,微服务之间的通信也通过API网关进行。
可以看出,API网关方式有如下优势。
- 为微服务的接口提供一个统一的抽象网关层,比如微服务提供的接口有很多类型,在网关层提供了统一规范的接口。
- 轻量的消息路由、格式转换功能。
- 统一控制安全、监控、限流等非业务功能。
- 每个微服务都变得更加轻量,非业务功能都在网关层统一处理,微服务只需要关注业务逻辑。
消息代理方式
微服务也可以通过异步方式来集成,通过队列和订阅主题实现消息的发布和订阅,一个微服务可以是消息的发布者,将消息通过异步方式发送到队列或者订阅主题下。 作为消费者的微服务可以从队列或者主题中获取消息,通过消息中间件将服务之间的直接调用解耦。
异步的生产者/消费者模式通常通过AMQP、MQTT等异步消息进行规范。
技术架构的设计原则如下
- 无状态,即尽量不要把状态数据保存在本机上。
- 可复用。
- 复用粒度是有业务逻辑的抽象服务,不是服务的实现细节。
- 服务引用只依赖服务抽象。
- 松耦合
- 跨业务域调用,尽可能异步解耦。
- 在同步调用时设置超时时间和队列大小。
- 将相对稳定的基础服务与易变流程服务分离。
- 可治理
- 服务可降级。
- 服务可限流。
- 服务可开关。
- 服务可监控。
- 白名单机制。
- 制定服务契约。
- 基础服务
- 基础服务下沉、可复用,例如时效、库存和价格计算。
- 基础服务自治、相对独立。
- 对基础服务的实现要精简,并可水平扩展。
- 对基础服务的实现要进行物理隔离,包括基础服务相关的数据。
负载均衡层
建议将负载均衡分成两级来处理,一级是流量四层分发,二级是应用层面七层转发(即业务层面)。 首先我们可以通过LVS或HAProxy将流量转发给二层负载均衡(一般为Nginx),即实现了流量的负载均衡,此处可以使用如轮询、权重等调度算法来实现负载的转发;然后二层负载均衡会根据请求特征再将请求分发出去。此处为什么要将负载均衡分为两层呢?
- 第一层负载均衡应该是无状态的,方便水平扩容。我们可以在这一层实现流量分组(内网和外网隔离、爬虫和非爬虫流量隔离)、内容缓存、请求头过滤、故障切换(机房故障切换到其他机房)、限流、防火墙等一些通用型功能,无状态设计,可以水平扩容。
- 二层Nginx负载均衡可以实现业务逻辑,或者反向代理到如Tomcat,这一层的Nginx与业务相关联,可以实现业务的一些通用逻辑。如果可能的话,这一层也应尽量设计成无状态,以方便水平扩容。
秒杀活动中的架构设计思想
- 限流:由于活动的库存量一般都很少,对应的只有少部分用户才能秒杀成功。所以我们需要限制大部分用户流量,只准许少量用户流量进入后端服务器。
- 削峰:秒杀活动开始的那一瞬间,会有大量用户冲击进来,所以在开始的时候会有一个瞬间流量峰值。如何把瞬间的流量峰值变得更加平缓,是能否成功设计好秒杀系统的关键因素。实现流量削峰填谷,一般是采用缓存和MQ中间件来解决。
- 异步:秒杀其实可以当作高并发系统来处理,这个时候,可以考虑从业务上做兼容,将同步的业务设计成异步处理的任务,以提高网站的整体可用性。
- 缓存:秒杀系统的瓶颈主要体现在下订单、扣减库存流程中。这些流程主要会用到OLTP的数据库,类似于MySQL、Oracle。由于数据库底层采用B+树的储存结构,对应地我们随机写入与读取的效率也会相对较低。如果我们把这部分业务逻辑迁移到redis中,则会极大地提高并发效率。
ngx_lua模块应用场景
理论上可以使用ngx_lua开发各种复杂的Web应用,不过Lua是一种脚本/动态语言,不适合业务逻辑比较重的场景,适合小巧的应用场景,代码行数保持在几十行到几千行。目前见到的一些应用场景有以下几种。
- Web应用:会进行一些业务逻辑处理,甚至进行耗CPU的模板渲染,一般流程为MySQL/redis/HTTP获取数据→业务处理→产生JSON/XML/模板渲染内容,比如京东的列表页或商品详情页。
- 接入网关:实现如数据校验前置、缓存前置、数据过滤、API请求聚合、AB测试、灰度发布、降级、监控等功能。
- Web防火墙:可以进行IP/URL/UserAgent/Referer黑名单、限流等功能。
- 缓存服务器:可以对响应内容进行缓存,减少到后端的请求,从而提升性能。
- 其他:如静态资源服务器、消息推送服务、缩略图裁剪等。
Hystrix实现服务隔离
Hystrix的核心是提供服务容错保护,并且其设计原则中就有一条:防止任何单一依赖使用掉整个容器(如Tomcat)的全部用户线程。 那么Hystrix是如何实现的呢?答案是舱壁隔离模式(Bulkhead Isolation Pattern)。 该模式来源于货船为了进行防止漏水和火灾的扩散,会将货仓分隔为多个,如果一个货舱进水了或发生火灾,只会损失一个船舱,可以保护其他货舱不受影响。 Hystrix使用该模式,可以对资源或失败单元进行隔离,避免一个服务的失效导致整个系统垮掉(雪崩效应)。
Hystrix实现服务隔离的思路如下:
- 使用命令模式(HystrixCommand/HystrixObservableCommand)对服务调用进行封装,使每个命令在单独线程中/信号授权下执行。
- 为每一个命令的执行提供一个小的线程池/信号量,当线程池/信号已满时,立即拒绝执行该命令,直接转入服务降级处理。
- 为每一个命令的执行提供超时处理,当调用超时时,直接转入服务降级处理。
- 提供断路器组件,通过设置相关配置及实时的命令执行数据统计,完成服务健康数据分析,使得在命令执行过程中可以快速判断是否可以执行,还是执行服务降级处理。
线程池隔离与信号量隔离
Hystrix提供了线程池隔离(Thread Pools)和信号量隔离(Semaphores)两种服务隔离策略。
- 线程池隔离:不同服务的执行使用不同的线程池,同时将用户请求的线程(如Tomcat)与具体业务执行的线程分开,业务执行的线程池可以控制在指定的大小范围内,从而使业务之间不受影响,达到隔离的效果。
- 信号量隔离:用户请求线程和业务执行线程是同一线程,通过设置信号量的大小限制用户请求对业务的并发访问量,从而达到限流的保护效果。
使用线程池隔离具有以下优点: - 应用系统会被完全保护起来,即使其中的一个服务线程池满了,也不会影响到应用的其他部分。 - 当引入一个新的客户端Lib的时候,如果发生问题,只会影响到新的服务,并不会影响其他服务。 - 当一个失败的服务恢复正常时,系统会立即恢复正常的性能; - 如果我们的应用系统一些参数配置错误,那么线程池的运行状况将会很快被检测出来,比如延迟、超时、拒绝等。同时可以通过动态属性实时执行来处理纠正错误的参数配置。 - 如果服务的性能有变化需要调整,比如增加或者减少超时时间,更改重试次数,就可以通过线程池指标动态属性修改,而且不会影响其他服务请求。 - 除了隔离优势外,Hystrix拥有专门的线程池可提供内置的并发功能,可以在同步调用之上构建异步外观模式,这样能很方便地做异步编程(Hystrix引入了Rxjava异步框架)。
但使用线程池隔离也有缺陷,主要缺陷就是它增加了计算的开销,每个业务请求(被包装成命令)在执行的时候,会涉及请求排队、线程调度、上下文切换等处理。不过Netflix公司内部认为线程隔离的开销已经很小了,不会产生重大的成本或性能影响。
Hystrix提供了熔断模式和隔离模式来解决或者缓解雪崩效应。这两种方案都属于阻塞发生之后的应对策略,而非预防性策略(如限流模式)。 Hystrix是在服务访问失败时降低阻塞的影响范围,避免整个服务被拖垮。
Netflix Zuul组件
Netflix Zuul组件可以用于反向代理功能,通过路由寻址将请求转发到后端的服务上,并增加一些通用逻辑处理。Zuul对请求提供了路由和过滤器两个功能,其中,路由功能负责将外部请求转发到具体的微服务实例上,是实现外部访问统一入口的基础。过滤器功能则负责对请求的处理过程进行干预,是实现请求校验、服务聚合等功能的基础。
通过Zuul组件,可以完成以下功能。
动态路由:Zuul路由服务器支持与Eureka服务器的整合,可以动态对注册到Eureka服务器中的微服务进行路由映射。另外,Zuul提供一系列的路由规则配置,可以针对生产中的实际情况进行配置,实现微服务路由的灵活控制。
- 监控与审查:通过对一些特定的接口设置访问白名单、访问次数、访问频率等各类设置,可以在不影响微服务实现的情况下,对访问实施监控和审查处理。
- 身份认证与安全:用户身份认证几乎是每一个应用的基础,如果由每个微服务系统单独实现该功能,显然比较浪费资源,而且使开发效率变低。通过Zuul可以将认证的部分单独抽取出来,让微服务系统无须关注认证的逻辑,只需要关注业务本身即可。另外,可以统一在服务网关层增加一个额外的保护层来防止恶意攻击,如果客户端直连微服务的话,则每个暴露的微服务都需要面临这个安全问题。
- 压力测试:通过Zuul所提供的过滤器功能可以逐渐增加对某一服务集群的流量,以了解服务性能,从而及早对服务运维架构做出调优。
- 金丝雀、A/B测试:新版本、新功能可能都需要测试用户对其的反应,通过API服务网关,可以轻松控制部分用户访问服务实例,并且可以对用户行为进行记录和分析,以便对新版本及新功能进行评价,获取应用的最优方案。
- 服务迁移:通过Zuul代理可以处理来自旧端点的客户端上的所有流量,将一些请求重定向到新的端点,从而慢慢地用不同的实现来替换旧端点。
- 负载剪裁/限流:为每一个负载类型分配对应的容量,对超过限定值的请求弃用,这样可以防止站点不被未知的大流量冲跨。通常,可以利用API服务网关配置一个阀值,当请求数超过该阀值时会直接返回错误,而不会运行剩下的逻辑。
实战:秒杀系统设计方案
秒杀系统设计要解决的问题如下:
- 突发性大量接口请求导致服务器高负载,此时需要用限流和削峰的方案进行处理。
- 如果突然增加的带宽超过服务商提供的带宽上限,则要注意数据传输的完整性,即从客户端向服务器传输数据时即使速度缓慢,也要保证数据的完整性,以免数据丢失导致相应的错误,此时需要用队列及分布式锁等方案进行处理。
- 秒杀时应通过减库存操作维持数据的一致性,以免造成重复下单(超买/超卖)、库存不足等现象。此时需要用网关及队列等方案进行处理。
- 在秒杀之前按钮应为灰色,之后在不刷新页面的情况下将按钮点亮。此处尽量隐藏URL,并对通信信息进行加密处理,以限制各种脚本请求,尽可能按F12键后查看不到各种地址及相关信息。
- 控制刷新页面,当用户即将参与秒杀时通常会不断按F5键刷新页面,重新加载页面同样会请求接口,应减少此种接口的请求,并将部分数据缓存至客户端,减轻服务器的压力。
秒杀系统需要达到限流、削峰、异步处理、高可用、缓存、可扩展等要求,具体如下:
- 限流:鉴于只有少部分用户能够秒杀成功,所以要限制大部分流量,只允许少部分流量进入服务后端。常见的限流有单一端口登录(同一账号只能单一端口登录,例如App与Web只允许一个端口正在登录)、只有登录账号才能参与秒杀、当单击按钮次数过多时应限制单击次数,例如,每个账号每秒只能单击3次等不同的限流方案。
- 削峰:因为秒杀系统瞬时会有大量用户涌入,所以在抢购一开始会出现瞬间峰值。高峰值流量是压垮系统的主要原因之一,如何把瞬间的高流量转变成一段时间的平稳的流量是设计秒杀系统很重要的思路。对流量进行削峰的解决方案是用消息队列缓冲瞬时流量,把同步的直接调用转换成异步的间接推送,中间通过一个队列在一端承接瞬时的流量洪峰,在另一端平滑地将消息推送出去。消息队列中间件主要解决应用耦合、异步消息、流量削峰等问题。常用的消息队列有ActiveMQ、RabbitMQ、ZeroMQ、Kafka、MetaMQ和RocketMQ等。削峰不是一次性可以解决的方案,而是要层层削峰,每一层都把压力降到最小,再传输给下一层,这样才能接受更大的压力与并发。
- 异步处理:秒杀系统是一个高并发系统,采用异步处理模式可以极大地提高系统并发量,其实异步处理就是削峰的一种实现方式。异步处理的设计不仅可以削峰,还可以减轻对缓存、数据库和I/O的压力。
- 高可用:所有服务器无论应用层还是数据层都要达到高可用的标准,即任何一台服务器宕机都可由其他服务器暂时替代,并通过自动或手动的方式迅速重启服务器,保证用户几乎感受不到服务器宕机。
- 缓存:秒杀系统最大的瓶颈一般都是数据库读写。由于数据库读写属于磁盘I/O,性能很低,如果能够把部分数据或业务逻辑转移到内存缓存,则会极大地提升效率。
- 可扩展:这里讲的可扩展指一旦性能无法支撑当前并发,则可以迅速通过提升服务器性能或快速平滑地增加集群服务器的方式,顶住当前高峰压力。当压力下降时,再通过自动或手动的方式,平滑地卸下集群内部的服务器。
Golang 中间件的使用
在API中可能使用限流、身份验证等。
Go语言中net/http设计的一大特点就是特别容易构建中间件。Gin框架也提供了类似的中间件支持。需要注意的是,在Gin里面中间件只对注册过的路由函数起作用。
对于分组路由,嵌套使用中间件,可以限定中间件的作用范围。大致分为全局中间件、单个路由中间件和分组中间件。
在高并发场景中,有时候需要用到限流降速的功能,这里引入一个限流中间件。有关限流方法常见有两种,具体可自行研究,这里只讲使用。
导入github.com/didip/tollbooth/limiter包,在上面代码基础上增加如下语句:
//rate-limit 限流中间件
lmt := tollbooth.New
Limiter(1, nil) lmt.SetMessage("服务繁忙,请稍后再试...")
修改并加入限流策略:
v.GET("/index.html", LimitHandler(lmt), handler.IndexHandler)
按F5键刷新http://localhost/index.html页面时,浏览器会显示:服务繁忙,请稍后再试...
限流策略的对象也可以是IP。
tollbooth.LimitByKeys(lmt, []string{"127.0.0.1", "/"})
微服务容错简介
设计微服务框架时需要加入容错措施,确保某一服务即使出现问题也不会影响系统整体可用性。这些措施包括:超时与重试(Timeout and Retry)、限流(Rate Limiting)、熔断器(Circuit Breaking)、回退(Backoff)、舱壁隔离(Bulkhead Isolation)等。下面简单介绍这几种容错措施。
- 超时与重试:在调用服务时,超出了限定的时间,这时的调用就是超时调用。对于超时,要采用一定的规则进行处理,这个规则就是超时机制。比如,针对网络连接超时、RPC响应超时的超时响应机制等。在分布式服务环境下,超时机制主要解决了当依赖服务出现网络连接或响应延迟、服务端线程占满、回调无限等待等问题时,调用方可依据设定的超时时间策略来采取中断调用或间歇调用,及时释放关键资源,避免无限占用某个系统资源而出现整个系统拒绝对外提供服务的情况。
- 限流:服务的容量和性能是有限的,限流机制主要限定了对微服务应用的并发访问。比如定义了一个限流阈值,当外部访问超过了这个限流阈值时,后续的请求就会遭到拒绝,这样就可以防止微服务应用在突发流量下或被攻击时被击垮。
- 熔断器:在微服务系统中,当服务的输入负载迅速增加时,如果没有有效的措施对负载进行切断,则服务会被迅速压垮,接着压垮的服务会导致依赖它的其他服务也被压垮,出现连锁反应并造成雪崩效应。因此,可在微服务架构中实现熔断器,即在某个微服务发生故障后,通过熔断器的故障监控,向调用方返回一个错误响应,调用方进行主动熔断。这样可以防止服务被长时间占用而得不到释放,避免了故障在分布式系统中的蔓延。如果故障恢复正常,服务调用也能自动恢复。
- 回退:指微服务系统在熔断或者限流发生时,采用某种处理逻辑,返回到以前的状态。这是一种弹性恢复能力。常见的处理策略有直接抛出异常、返回空值或默认值,以及返回备份数据等。回退机制是保证微服务系统具有弹性恢复能力的机制。
- 舱壁隔离:这里借用了造船行业里的概念,轮船上往往会对一个个船舱进行隔离,这样一个船舱漏水不会影响其他船舱。同样的道理,舱壁隔离措施就是采用隔离手段把各个资源分隔开。当其中一个资源出现故障时,只会损失一个资源,其他资源不受影响。线程隔离(Thread Isolation)就是舱壁隔离的常见场景之一。
对象重用
下面是JDK和Java EE中重用对象的一些例子,以及重用的原因:
- 线程池: 线程初始化的成本很高。
- JDBC池: 数据库连接初始化的成本很高。
- EJB池: EJB初始化的成本很高(参见第10章)。
- 大数组: Java要求,一个数组在分配的时候,其中的每个元素都必须初始化为某个默认值(null 、0或者false,根据具体情况而定)。对于很大的数组,这是非常耗时的。
- 原生NIO缓冲区: 不管缓冲区多大,分配一个直接的java.nio.Buffer (即调用allocateDirect()方法返回的缓冲区),这个操作都非常昂贵。最好是创建一个很大的缓冲区,然后通过按需切割的方式来管理,以便将其重用于以后的操作。
- 安全相关类: MessageDigest、Signature以及其他安全算法的实例,初始化的成本都很高。基于Apache的XML代码就是使用线程局部变量保存这些实例的。
- 字符串编解码器对象: JDK中的很多类都会创建和重用这些对象。在大多数情况下,这些还是软引用,下一节将介绍。
- StringBuilder协助者: BigDecimal类在计算中间结果时会重用一个StringBuilder对象。
- 随机数生成器:Random类和(特别是)SecureRandom类,生成它们的实例的代价是很高的。
- 从DNS查询到的名字: 网络查询代价很高。
- ZIP编解码器: 有一种有趣的变化,初始化的开销不是特别高,但是释放的成本很高,因为这些对象要依赖对象终结操作(finalization)来确保释放掉所用的原生内存。更多细节,参见7.3.2节的“终结器和最终引用”。
此处讨论的对象池和线程局部变量两种方式,在性能上有些差别。下面详细看一下。
对象池
对象池不受人喜欢,原因有多个方面,只有部分原因和性能有关。线程池的大小可能很难正确地设置,它们将对象管理的负担又抛给程序员了:程序员不能简单地将对象丢出作用域,而必须记得将其返还到对象池中。
不过这里的焦点是对象池的性能,它受如下几个因素的影响。
- GC影响: 如我们所见,保存大量对象会降低GC的效率(有时非常显著)。
- 同步: 对象池必然是同步的,如果对象要频繁地移除和替换,对象池上可能会存在大量竞争。其结果是,访问对象池可能比初始化新对象还慢。
- 限流(Throttling): 对象池对性能也有正面的影响:对于对稀缺资源的访问,线程池可以起到限流作用。如第2章所讨论的,如果想增加的负载超出系统的处理能力,性能将下降。这是线程池之所以很重要的一个原因。如果有太多线程同时运行,CPU将不堪重负,而且性能会下降(第9章就有个这方面的例子)。 这一原则也适用于远程系统的访问,而且在JDBC连接中会经常见到。如果JDBC连接数超出数据库的处理能力,数据库的性能就会下降。在这些情况下,通过确定池的上限来限制资源数(如JDBC连接数)更好,即便这意味着应用中的线程必须等待一个空闲资源。
线程局部变量
在通过将对象保存为线程局部变量这种技术实现对象重用时,有不同的性能权衡,如下所列。
- 生命周期管理: 线程局部变量要比在池中管理对象更容易,成本更低。这两种技术都邀请开发者去获取初始对象:或者是从对象池中检出,或者是在线程局部对象上调用get() 方法。但是对象池还要求开发者在使用完毕后归还对象(否则其他人就不能使用了);线程局部对象在线程内总是可用的,不需要显式地归还。
- 基数性(Cardinality): 线程局部变量通常会伴生线程数与保存的可重用对象数之间的一一对应关系。不过并非严格如此。线程的变量副本,直到该线程第一次访问它时,才会创建,因此保存的对象数有可能小于线程数。但是保存的对象数不可能会超过线程数,大部分时间两者是相同的。 另一方面,对象池的大小则有些随意。如果一个Servlet有时需要一个JDBC连接,有时需要两个,则JDBC池的大小可以相应设定(比如说,对于8个线程,设定12个连接)。线程局部变量做不到这一点,也不能减少对资源的访问(除非线程数本身可以减少)。
- 同步: 线程局部变量不需要同步,因为它们只能用于一个线程之内;而且线程局部的get()方法相当快。(情况并非一直如此,在早期的Java版本中,获得一个线程局部变量的开销很大。如果过去因为差劲的性能而远离了线程局部变量,在当前的Java版本中,可以重新考虑一下。) 同步还带来了一个有趣的问题,因为线程局部对象的性能优势通常会用节省了同步的代价来表达(而不说这是重用对象的好处)。比如,Java 7引入了一个ThreadLocalRandom 类;这个类(而不是一个Random实例)也用到了示例股票应用中。此外,本书中的很多例子在Random对象的next()方法上都会遇到一个同步瓶颈。使用线程局部对象是避免同步瓶颈的好方法,因为只有一个线程能使用这个对象。 然而,只要让这个例子每次需要时,就简单地创建一个新的Random实例,同步问题也能轻松解决。不过,这样解决同步问题对整体性能没什么帮助:初始化一个Random对象的开销非常大,而且持续创建这个类的实例,与在多个线程间共享一个类实例的同步瓶颈相比,性能可能更差。 使用ThreadLocalRandom类性能会更好,如表7-4所示。这个例子使用了batching stock应用,对于每支股票,有创建新的Random实例和重用ThreadLocalRandom两种方案。
微服务技术体系也有自身的结构
微服务技术体系可以映射到其中的4个特征。
- 一是微服务和组件的关系。微服务就是组件的一种服务包装。
- 二是智能终端与哑管道。智能终端即客户端,就是要加强客户端的功能,使客户端服务职责单一,处理迅速,反馈及时;哑管道就是网络及通信,弱化哑管道就是尽量采用轻量级的通信处理机制。
- 三是基础设施自动化。基础设施自动化主要是指软硬件设施以及需求、设计、开发、部署、运维等相关工具链的自动化。
- 四是容错设计。由于外部环境不可预料,因此微服务技术体系提供重试机制、限流、熔断机制、负载均衡、降级等容错设计。
德邦快递技术实践
在早期,德邦快递的技术部门采用开源且较为成熟的Dubbo作为微服务框架。 在改造后期,由于Dubbo在服务治理上具有不支持熔断、限流、降级等功能的缺点以及集成管理复杂性,不能契合快递的产品特性和运营特性。 德邦快递选择与网易云一起深入探索、完善微服务框架,不断分析讨论后确定了德邦快递的改造侧重点: 1. 一是服务的拆分和服务发现; 2. 二是数据库的横向扩展; 3. 三是熔断限流降级; 4. 四是全链路的压测。
针对企业痛点,网易云制定了如下解决方案。
首先向物流常用的地理信息系统(GIS)提供微服务框架及工具链,保障服务标准、服务治理以及服务问题追踪,降低了改造风险。 在高并发的情况下,采用网易公司的分布式数据库,以支撑更大的业务量,给横向扩展带来了保障。同时通过容器化改造,缩短了软件的发布周期。 可定制化的API网关,实现了定期维护、定期下线、定期上线的需求。并且在API网关上对文档进行自动管理,确保数据一致性,减少了业务团队间的沟通成本。 增加黑白名单和权限控制的可配置路由,使互信的管理粒度更加细腻化。 在熔断与容错上,将SpringCloud和Dubbo结合,可在方法级别上进行服务治理。最后构建可视化的应用运维监控平台,简化操作,保证了运行稳定性。
这样一来,借助网易云轻舟微服务平台,德邦快递通过构建统一的产品服务中心,有效提升了资源利用率,节约了大量成本,实现了敏捷迭代、质量提升、智能运维和按需扩容的需求,全面提升了数字化竞争力。
微服务架构
微服务(Microservice Architecture)是一种架构概念,它将功能分解成不同的服务,降低系统的耦合性,提供更加灵活的服务支持,各个服务之间通过API接口进行通信。从微服务架构的设计模式来看,它包含开发、测试、部署和运维等多方面因素,本节从开发角度讲述如何搭建微服务架构。
微服务实现原理
传统的开发模式使用单体式开发,即所有网页功能在一个Web应用中实现,然后在某个服务器部署上线。当网站的访问量或数据量过大时,将导致单体式系统的某个功能出现异常,整个网站也随之瘫痪。
对于大型网站来说,微服务架构可以将网站功能拆分为多个不同的服务,每个服务部署在不同的服务器,每个服务之间通过API接口实现数据通信,从而构建网站功能。服务之间的通信需要考虑服务的部署方式,比如重试机制、限流、熔断机制、负载均衡和缓存机制等因素,这样能保证每个服务之间的稳健性。微服务架构一共有6种设计模式,每种模式的设计说明如下:
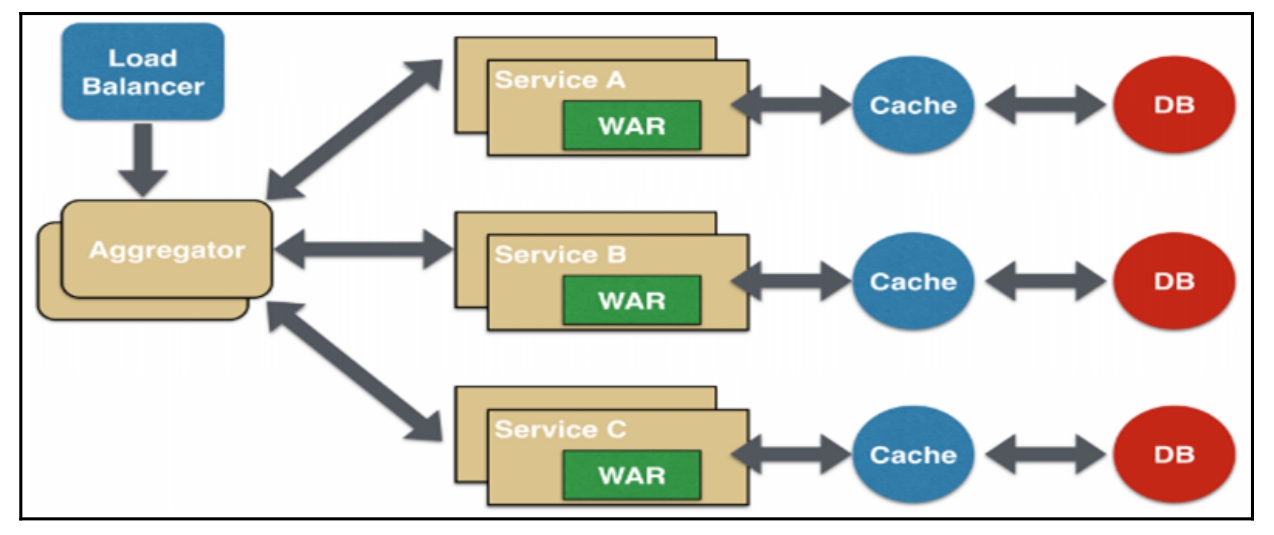
- 聚合器微服务设计模式:聚合器调用多个微服务实现应用程序或网页所需的功能,每个微服务都有自己的缓存和数据库,这是一种常见的、简单的设计模式,其设计原理如图16-7所示。
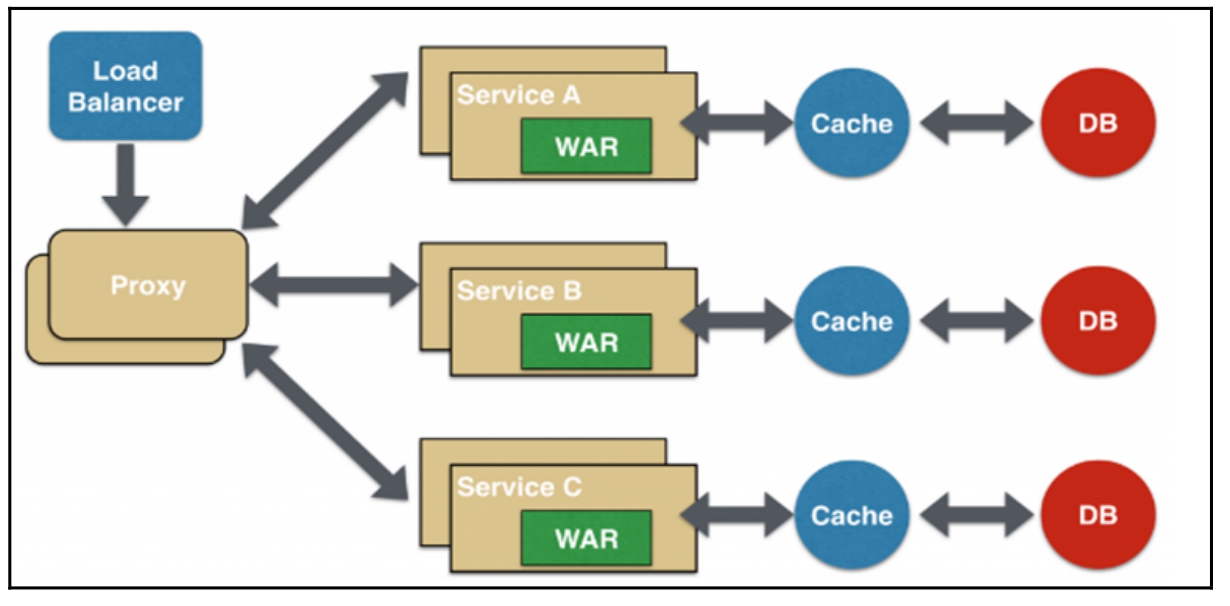
- 代理微服务设计模式:这是聚合器微服务设计模式的演变模式,应用程序或网页根据业务需求的差异而调用不同的微服务,代理可以委派HTTP请求,也可以进行数据转换工作,其设计原理如图16-8所示。
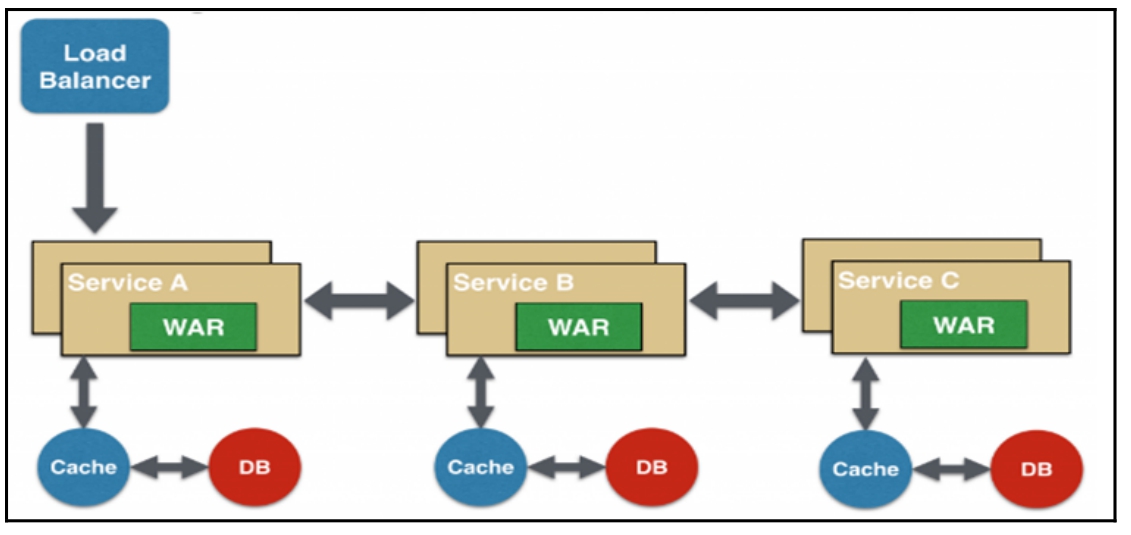
- 链式微服务设计模式:每个微服务之间通过链式方式进行调用,比如微服务A接收到请求后会与微服务B进行通信,类似地,微服务B会同微服务C进行通信,所有微服务都使用同步消息传递。在整个链式调用完成之前,浏览器会一直处于等待状态,其设计原理如图16-9所示。
- 分支微服务设计模式:这是聚合器微服务设计模式的扩展模式,允许微服务之间相互调用,其设计原理如图16-10所示。
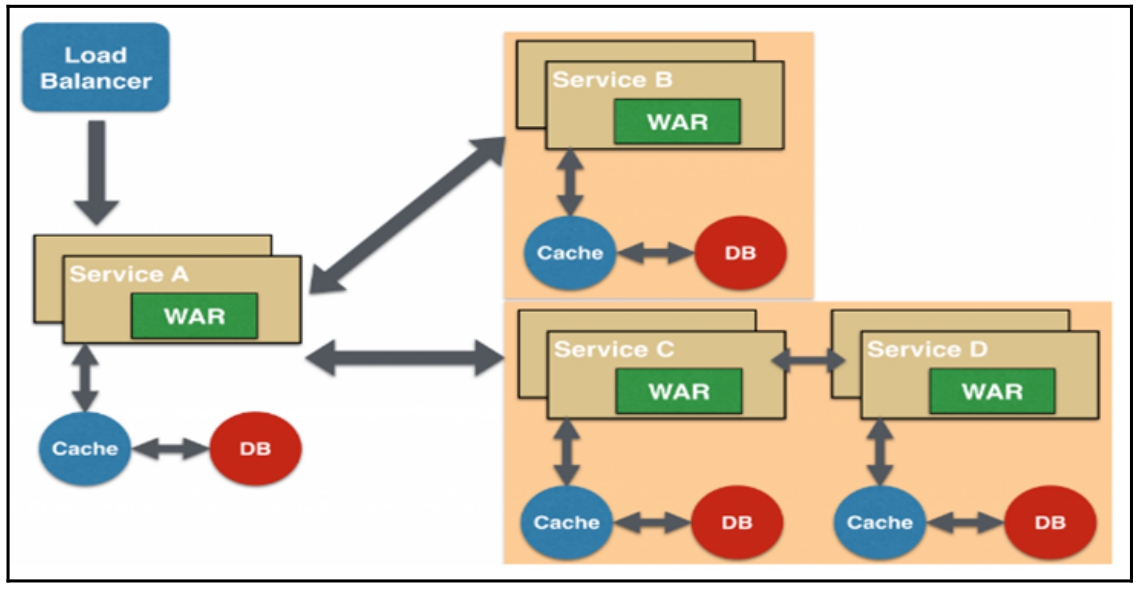
- 数据共享微服务设计模式:部分微服务可能会共享缓存和数据库,即两个或两个以上的微服务共用一个缓存和数据库。这种情况只有在两个微服务之间存在强耦合关系时才能使用,对于使用微服务实现的应用程序或网页而言,这是一种反模式设计,其设计原理如图16-11所示。
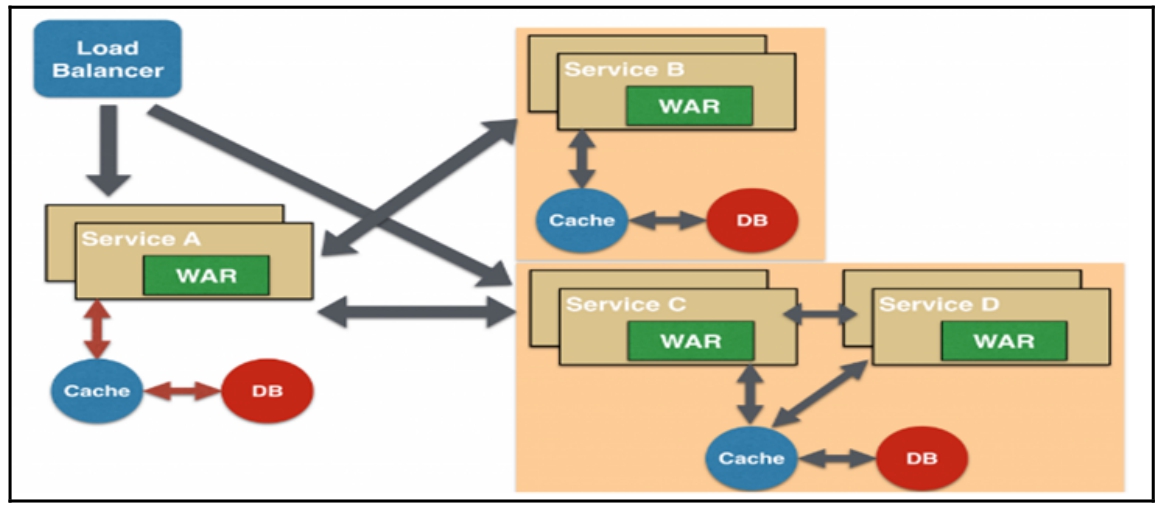
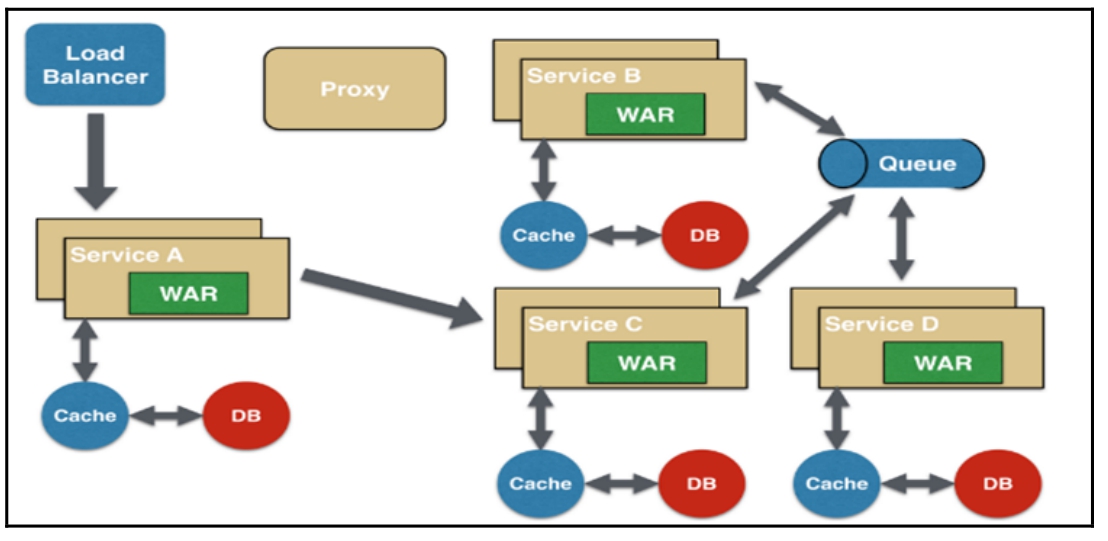
- 异步消息传递微服务设计模式:由于API接口使用同步模式,如果API接口执行的程序耗时过长,就会增加用户的等待时间,因此某些微服务可以选择使用消息队列(异步请求)代替API接口的请求和响应,其设计原理如图16-12所示。
微服务设计模式不是唯一的,具体还需要根据项目需求、功能和应用场景等多方面综合考虑。对于微服务架构,架构的设计意识比技术开发更为重要,整个架构设计需要考虑多个微服务的运维难度、系统部署依赖、微服务之间的通信成本、数据一致性、系统集成测试和性能监控等。
前后端分离小结
随着前端技术的发展,三大主流框架(Vue、React和Angular)成为网站开发的首选框架,前后端分离已成为互联网项目开发的业界标准使用方式。 在前后端分离的基础上,后端系统的架构设计也随之改变,微服务架构应运而生。
前后端分离可以将网页的路由地址、业务逻辑和网页的数据渲染交给前端开发人员实现,后端人员只需提供API接口即可。 在整个网站开发过程中,后端人员提供的API接口主要实现数据库的数据操作(增、删、改、查),并将操作结果传递给前端;前端人员负责网页的样式设计、定义网页的路由地址、访问API接口获取数据、数据的业务逻辑处理和数据渲染操作等。
若选择Django作为前后端分离的后端服务器系统,则功能配置方法如下:
- 将配置属性INSTALLED_APPS和MIDDLEWARE的部分功能去除,如Admin后台系统、静态资源和消息框架等功能。
- 注释配置属性TEMPLATES和STATIC_URL,移除模板功能和静态资源的路由设置。
- 将新建的项目应用添加到配置属性INSTALLED_APPS,并在配置属性DATABASES中设置数据库的连接方式。
微服务(Microservice Architecture)是一种架构概念,它将功能分解成不同的服务,降低系统的耦合性,提供更加灵活的服务支持,各个服务之间通过API接口进行通信。从微服务架构的设计模式来看,它包含开发、测试、部署和运维等多方面因素。
微服务架构可以将网站功能拆分为多个不同的服务,每个服务部署在不同的服务器,每个服务之间通过API接口实现数据通信,从而构建网站功能。 服务之间的通信需要考虑服务的部署方式,比如重试机制、限流、熔断机制、负载均衡和缓存机制等因素,这样能保证每个服务之间的稳健性。
微服务架构一共有6种设计模式,每种模式的设计说明如下:
- 聚合器微服务设计模式:聚合器调用多个微服务实现应用程序或网页所需的功能,每个微服务都有自己的缓存和数据库,这是一种常见的、简单的设计模式。
- 代理微服务设计模式:这是聚合器微服务设计模式的演变模式,应用程序或网页根据业务需求的差异而调用不同的微服务,代理可以委派HTTP请求,也可以进行数据转换工作。
- 链式微服务设计模式:每个微服务之间通过链式方式进行调用,比如微服务A接收到请求后会与微服务B进行通信,类似的,微服务B会同微服务C进行通信,所有微服务都使用同步消息传递。在整个链式调用完成之前,浏览器会一直处于等待状态。
- 分支微服务设计模式:这是聚合器微服务设计模式的扩展模式,允许微服务之间相互调用。
- 数据共享微服务设计模式:部分微服务可能会共享缓存和数据库,即两个或两个以上的微服务共用一个缓存和数据库。这种情况只有在两个微服务之间存在强耦合关系才能使用,对于使用微服务实现的应用程序或网页而言,这是一种反模式设计。
- 异步消息传递微服务设计模式:由于API接口使用同步模式,如果API接口执行的程序耗时过长,就会增加用户的等待时间,因此某些微服务可以选择使用消息队列(异步请求)代替API接口的请求和响应。
微服务设计模式不是唯一的,具体还需要根据项目需求、功能和应用场景等多方面综合考虑。 对于微服务架构,架构的设计意识比技术开发更为重要,整个架构设计需要考虑多个微服务的运维难度、系统部署依赖、微服务之间的通信成本、数据一致性、系统集成测试和性能监控等。
功能的拆分方式并非固定不变,一般遵从以下原则:
- 单一职责、高内聚低耦合。
- 服务粒度适中。
- 考虑团队结构。
- 以业务模型切入。
- 演进式拆分。
- 避免环形依赖与双向依赖。
微服务架构设计常用于大型网站系统,因此微服务的每个阶段实现的功能如下:
- 开发阶段根据微服务架构设计模式进行功能拆分,将功能拆分成多个微服务,并且统一规范设计每个微服务的API接口,每个API接口符合RESTful设计规范。如果服务之间部署不同的服务器,就需要考虑跨域访问。
- 测试阶段用于验证各个服务之间的API接口的输入输出是否符合开发需求,还需要验证各个API接口之间的调用逻辑是否合理。
- 部署阶段根据部署方案执行,部署方案需要考虑服务的重试机制、缓存机制、负载均衡和集群等部署方式。
- 运维监控阶段需要对网站系统实时监控,监控内容包括:日志收集、事故预警、故障定位和系统性能跟踪等,并且还要根据监测结果适当调整部署方式。
Serverless
技术特点
随着以Kubernetes为代表的云原生技术成为云计算的容器界面,Kubernetes成为云计算的新一代操作系统。 面向特定领域的后端云服务(BaaS)则是这个操作系统上的服务API,存储、数据库、中间件、大数据、AI等领域的大量产品与技术都开始提供全托管的云形态服务,如今越来越多的用户已习惯使用云服务,而不是自己搭建存储系统、部署数据库软件。
当这些BaaS云服务日趋完善时,Serverless因为屏蔽了服务器的各种运维复杂度,让开发人员可以将更多精力用于业务逻辑设计与实现,而逐渐成为云原生主流技术之一。
Serverless计算包含以下特征。
- 全托管的计算服务:用户只需要编写代码构建应用,无须关注同质化的、负担繁重的服务器等基础设施的开发、运维、安全、高可用等工作。
- 通用性:结合云BaaS API的能力,能够支撑云上所有重要类型的应用。
- 自动的弹性伸缩:用户无须为资源的使用提前进行容量规划。
- 按量计费:企业的使用成本得到有效降低,无须为闲置资源付费。
Serverless的三大核心价值如下。
- 快速交付:Serverless通过进行大量的端对端整合以及云服务之间的集成,为应用开发提供了最大化的便利性,让开发者无须关注底层的IaaS资源,而是更专注于业务逻辑开发,聚焦于业务创新,大大缩短了业务的上市时间。
- 极致弹性:在Serverless之前,一旦遇到突发流量,可能就会直接导致各种超时异常,甚至是系统崩溃。即使有限流保护以及提前扩容等手段,也依然会出现评估不准的情况,进而引发灾难性的后果。有了Serverless之后,由于它具备毫秒级的弹性能力,应对突发流量会变得更加从容。
- 更低成本:就跟生活中使用“水电煤”一样,我们只为实际消耗的资源买单,而无须为闲置的资源付费。Serverless提供的端到端的整合能力,极大地降低了运维的成本与压力,使NoOps成为可能。
基于快速交付、极致弹性、更低成本的三大核心价值,Serverless被认为是云时代的全新计算范式,引领云在下一个十年乘风破浪。 那么,下一个十年的Serverless将会有什么趋势呢?
- 标准开放。通过支持开源的工具链和研发框架,Serverless能够在多云环境下使用,无厂商锁定,免除用户后顾之忧。
- 与云原生结合。阿里云Serverless将借助容器出色的可移植性和灵活性,实现应用交付模式统一。通过复用云原生生态,Serverless在存储、网络、安全、可观测等方面更加标准、强大。
- 事件驱动。通过采用统一的事件标准,如CloudEvent来建立云上的事件枢纽,让Serverless开发集成云服务、云边端应用更简单。
- 解锁更多业务类型。Serverless早已不再局限于代码片段、短任务、简单逻辑,长时间运行、大内存的任务,有状态的应用,以及GPU/TPU的异构计算任务都会在Serverless产品上得到支持。
- 更低成本。在使用成本方面,采用Serverless产品的TCO会比基于服务器自建更低。一方面,引入预付费等计费模式,比按量计费节省30%以上的费用;另一方面,随着Serverless的不断演进,资源池更大、资源利用率更高,成本会被进一步压低。在迁移成本方面,可以通过选择不同形态的Serverless产品,采用迁移工具,甚至一行代码不改,存量应用就能迁移到Serverless,享受Serverless红利。
云原生微服务平台具有以下的功能
全托管的高可用容器集群。
- 一键生成运行镜像。代码和环境绑定后直接推送到镜像仓库,开发人员无须关注Dockerfile,即点即生成运行镜像。
- 可视化CI/CD。自动化对接部署流水线,用定制的流水线模板快速完成从构建到部署整个流程。
- 服务程序一键部署。可以一键部署应用程序到容器集群中,无须深入理解Kubernetes即可对服务实施升级、扩容、版本控制等运维操作。
- 多可用区,高可用性。通过平台可快速实现系统架构的多可用区部署,轻松构建同城或者异地的多活及灾备业务架构。
全面的服务治理。
- 细粒度的流量管控。通过扩展开源产品Envoy,实现了在HTTP上细粒度的灰度发布、蓝绿发布、限流限频、熔断、故障注入等微服务治理功能。
- 无代码侵入。深度整合了流量入口网关和服务网格Istio,服务治理对开发语言无依赖,可选用C++、Go、PHP、Swoole、Nodejs、Python等任何语言开发服务。
- 多种服务发现和负载均衡方法。支持K8S Service、K8S EndPoints列表等服务发现方法,提供轮询、一致性哈希、随机方法,甚至客户端自定义的负载均衡方法。
- 动态下发,实时生效。具有可视化配置路由转发、权限管控、请求转换、访问统计等几十种服务治理配置或插件,更改后实时生效。
低学习成本,高效率开发。
- 一体化的云原生解决方案。平台全方位对接多种云服务,业务无感知使用日志、镜像仓库、存储等基础能力,在充分使用云上弹性资源能力的同时,极大减少了上云的适配工作。
- 立体化的监控能力。内置监控中心,以指标和日志方式,从资源使用、网络调用、服务自定义指标3个维度,通过采集从底层机器到业务模块的200多个指标进行立体化监控。
- 自研云、公有云同种架构,提供一致的用户体验和运维管理。支持将服务低成本地部署到海外公有云集群中。
可用性下降一般有以下原因。
- 发布:如版本变更。
- 故障:服务不可用(进程Crash、物理机损坏、业务逻辑错误等)。
- 流量压力:超过服务能力上限等。
- 外部强依赖:依赖的关键服务错误会直接导致服务整体不可用。
HZERO架构
本节从“功能架构”与“微服务架构”两个维度,对HZERO架构做概要说明。
功能架构
HZERO采用 J2EE 技术体系,基于Spring Cloud微服务框架进行封装,平台设计灵活,可扩展、可移植、可应对高并发需求。同时兼顾本地化、私有云、公有云部署,支持SaaS模式应用。
- 基础服务:包括平台应用基础和服务治理两部分,是平台底层应用的基础服务,是一个微服务系统运行所必要的组件服务。平台提供较好的兼容性,可根据需要选择不同的基础组件,如注册中心、配置中心、分布式事务等,并能很好地适配阿里云EDAS、百度CNAP等公有云平台。
- ①认证服务:基于 Spring Security、Spring OAuth2、JWT实现的统一认证服务中心,登录基于Spring Security的标准登录系统。Web端采用简化模式(implicit)登录系统,移动端可使用密码模式(password)登录系统,并支持基于 Spring Social 的三方账号登录方式(如微信)。
- ②身份管理服务:权限管理服务,平台统一的权限体系架构,主要提供租户、角色、菜单、账户、单据数据权限等管理功能。
- ③网关服务:基于Spring Cloud Gateway的微服务网关服务,主要提供服务的路由、API鉴权、Token转JWT等功能。
- ④接口文档服务:基于Swagger拓展的API文档服务,主要提供在平台开发阶段的API文档管理和API调试等功能。
- ⑤注册中心服务:基于Eureka的平台注册中心服务,主要提供服务的注册发现等功能。
- ⑥配置中心服务:基于Spring Cloud Config改造的配置中心服务,主要提供服务的统一配置管理、服务路由、熔断限流等管理功能。
- ⑦平台治理服务:提供HZERO通用基础功能,主要涵盖平台开发支持模块、平台主数据模块、系统管理模块等;提供客户端组件,使开发者能够迅速、便捷地使用平台服务提供的功能,如值集、编码规则、配置、规则引擎、数据源管理等。
- 辅助开发包:主要针对开发人员进行技术开发支持,提供一系列通用的开发工具包,定义了基础工具类,如配置、缓存、消息、图形验证码等工具,减少开发人员重复造轮子,帮助提高代码编写效率。
- 开发组件:主要包含通用的Starter组件,如Excel导入导出、数据防篡改等,另外包含服务客户端组件,便于技术开发过程中,快速使用通用服务提供的能力。
- ①Mybatis增强组件:增强ORM框架Mybatis的数据库DML处理能力,支持分页,支持数据多语言、基于对象的CURD编写、数据防篡改、数据加密解密等功能。
- ②数据导出组件:基于Apache POI 4.0.0开发,使用SXSSF支持大数据量导出,导出格式为xlsx。在项目中只需依赖该jar包,再结合三个注解即可完成数据的导出。对于导出Excel样式,提供了两种默认实现,同时支持自定义导出样式。
- ③分布式锁组件:基于Redisson开发,开发中可以通过注解的方式进行分布式锁控制,使项目进行分布式锁变得非常简单。
- ④长连接组件:支持前端websocket和sock-js两种连接方式,用于后端的主动消息推送等场景。
- ⑤Redis操作组件:统一封装常用的Redis操作功能,使得在系统开发中操作Redis变得更加简单。
- ⑥三方登录组件:基于Spring Social开发,使系统通过配置的方式,快速地与微信、微博等开发平台进行整合,实现系统账户绑定、账户登录等功能。
- 通用服务:主要指平台中已包含的开发业务系统所需要的基础服务,如分布式调度、消息、权限、文档、支付管理等,能快速适配各产品线、各业务系统的通用基础功能需求,帮助提高开发效率。
- ①报表服务:通过配置数据源、报表数据集等信息,应用标准SQL、标签化SQL查询数据的方式,生成基于HTML平面报表、基于RTF模板的单据报表,并能够进行多种格式的报表文件导出等功能。
- ②消息服务:支持短信、邮箱、站内消息发送,能够灵活管理消息模板和对接多种云平台短信能力,如阿里云、百度云、腾讯云的短信服务,并支持多种类型消息混合发送、消息发送状态监控等功能。
- ③分布式调度服务:基于Quartz的分布式调度平台,服务端负责任务调度,任务的执行由执行器来完成。该服务具体包含执行器管理、并发任务管理、日志管理以及并发请求等功能。
- ④文件管理服务:对接多种云存储(百度云、阿里云、腾讯云、华为云、AWS等)、本地存储的文件管理服务,能够通过配置对文件上传进行控制,同时支持文件的汇总查询。
- ⑤通用导入服务:通用Excel、CSV文件导入服务,支持配置导入模板配置,导入模板下载,支持同步或异步的导入模式,上传数据自动校验规则控制,并能通过配置插入到指定数据库表等功能。
- ⑥平台前端:平台默认的前端应用,即支撑HZERO各服务组件的前端各配置、管理、应用页面。基于React技术开发,对Ant Design进行了封装,形成HZERO UI组件库,拥有更适配企业级中后台产品的交互语言和视觉风格,并采用模块化方式,便于开发引用和服务升级。
- 基本功能:HZERO平台提供的通用业务功能,目前主要包括平台管理、门户管理、报表管理及门户管理等业务系统所必需的一系列基础功能。
微服务架构
HZERO提供一套完整的基于Spring Cloud并且支持Dubbo的微服务开发框架。 以此微服务开发架构以及容器为微服务提供轻量级、面向应用的虚拟化运行环境和理想载体,并以Kubernetes作为容器编排工具,帮助企业方便快捷地构建组合微服务应用。
- 控制项目复杂度:将原来的单体式应用拆解成多个服务运行在不同进程中,这样可以只针对相应的服务进行修改,部署对应的服务进程,控制复杂性。
- 业务模块化,独立开发,加速迭代:松耦合的结构,让每个开发团队都可以根据自身情况去选择更适合的技术与工具,进行更有效、更灵活的开发。
- 独立部署,提升效率:将复杂的业务逻辑根据功能剥离开来,让它们具备独立的进程,每个服务就可以独立编译打包部署。
- 错误隔离:每个服务都具有独立性,以提高系统的容错性。不会因为单一服务发生延迟,导致所有应用资源(线程,队列等)被耗尽,从而避免造成雪崩效应
服务“挂”了怎么办
用传统方式开发服务的风险是,把所有鸡蛋放在一个篮子里,一荣俱荣,一损俱损。而分布式最大的前提就是假设网络是不可靠的,通过服务拆分来降低这个风险。 不过,如果没有可靠的保障,结局依然是噩梦。如果系统是由一系列服务调用链组成的,必须确保任一环节出问题都不至于影响整体链路。 相应的手段有很多,举例如下。
- 重试机制。
- 限流。
- 熔断机制。
- 负载均衡。
- 降级(本地缓存)
性能测试的术语和指标
性能测试中会涉及很多性能相关的指标和术语,本节重点剖析核心的概念。
- 在线用户,表示某个时间段内在服务器上保持登录状态的用户。但在线用户不一定是对服务器产生压力的用户,只有正在操作的活跃用户才会对服务器产生压力,在线只是一种状态。
- 相对并发用户,类似活跃用户,表示某个时间段内与服务器保持交互的用户,理论上这些用户有同一时刻(即绝对并发)进行操作的可能(对这种可能性的度量称为并发度)。相对并发的说法主要是为了区分绝对并发。
- 绝对并发用户,表示同一时间点(严格地说是足够短的时间段内)与服务器进行交互的用户,一般通过测试工具提供的并发控制(如JMeter的集合点)实现。
- 思考时间,表示用户每个操作后的暂停时间,或者叫作操作之间的间隔时间,此时间内用户是不对服务器产生压力的。如果想了解系统在极端情况下的性能表现,可以设置思考时间为0;而如果要预估系统能够承受的最大压力,就应该尽可能地模拟真实思考时间。
- 响应时间,通常包括网络传输请求的时间、服务器处理的时间,以及网络传输响应的时间。而我们重点关心的应该是服务器处理的时间,这部分受到代码处理请求的业务逻辑的影响,从中可以真正发现缺陷并对业务逻辑进行优化,而网络传输请求和响应的时间很大程度上取决于网络质量。 响应时间也就是JMeter术语中的Elapsed time,表示接收完所有响应内容的时间点减去请求开始发送的时间点。另外,Latency time表示接收到响应的第一个字节的时间点减去请求开始发送的时间点,Connection time表示建立连接所消耗的时间。 当关注响应时间时,不应该只关注平均响应时间。通常我们会采用95%的响应时间,即所有请求的响应时间按照从小到大排列,位于95% 的响应时间。该值更有代表性,而平均响应时间未能有效地考虑波动性。
- TPS,指每秒处理的事务数,是直接反映系统性能的指标。该值越大,系统性能越好。通常如果一个事务包含的请求就1个,那么这个值就是每秒处理请求数。另外还有个概念叫吞吐量,它除了用于描述网络带宽能力,也指单位时间内系统处理的请求数量,JMeter聚合报告中TPS就是用该术语显示的。假如1个用户在1s内完成1笔事务,则TPS明显就是1;如果某笔业务响应时间是1ms,则1个用户在1s内能完成1000笔事务,则TPS就是1000了;如果某笔业务响应时间是1s,则1个用户在1s内只能完成1笔事务,要想TPS达到1000,则至少需要1000个用户。因此在1s内,1个用户可以完成1000笔事务,1000个用户也可以完成1000笔事务,这取决于业务响应时间。
- TPS波动范围。方差和标准差都是用来描述一组数据的波动性的(表现数据集中还是分散),标准差的平方就是方差。方差越大,数据的波动越大。
提示
- 高并发:并发强调多任务交替执行,并发与并行是有区别的,并行是多任务同时执行。例如,一个核的CPU处理事务就是并发;多个核的CPU就会存在事务的并行处理。这里涉及的知识点包括多线程、事务和锁,设计高并发通常采用无状态、拆分、服务化、服务隔离、消息队列、数据处理和缓存等。
- 高可用:用系统的无故障运行时间来度量,主要作用为保证软件故障监控、数据备份和保护、系统告警、错误隔离。业务层设计包括集群、降级、限流、容错、防重和幂等。数据库设计包括分库、分表和分片等
面对流量洪峰的策略如下
- 服务降级。服务降级是指在特定情况下,例如“双十一”“双十二”期间,当流量超过系统服务能力时,跳过特定的处理流程。比如在一个买家下单后,我们可能需要进行风险评估、数据校验等一系列流程,当发生服务降级时,就跳过了数据校验逻辑,以避免用户长时间等待,降低对下游链路的冲击,保证服务的稳定性。服务降级是面对流量洪峰保证用户体验和预防系统崩溃的有效手段。
- 服务限流。服务限流是指根据服务的处理能力提前预估一个阈值,当流量大于该阈值时放弃处理直接返回错误。服务限流是应对流量达到峰值时,系统进行自我保护的重要措施。例如“双十一”零点下单峰值、余额宝九点抢购峰值以及活动结束商品信息编辑峰值,都需要进行相应的限流来保护系统。
- 故障容灾。单机系统的容灾能力几乎为零,一旦服务崩溃就马上变成不可用。分布式系统通过异地多活,可以不间断地提供服务。同时,借助于Nginx、Apache进行负载均衡可以进一步提高可用性。
实际上,即便进行了负载均衡和服务分布式部署,系统仍然面临容灾问题。现在的大型服务,例如淘宝、天猫、微信、京东都进行了异地多活的部署。异地多活部署的主要目的是,通过多机房提供服务来降低单机房故障带来的影响,提高容灾能力
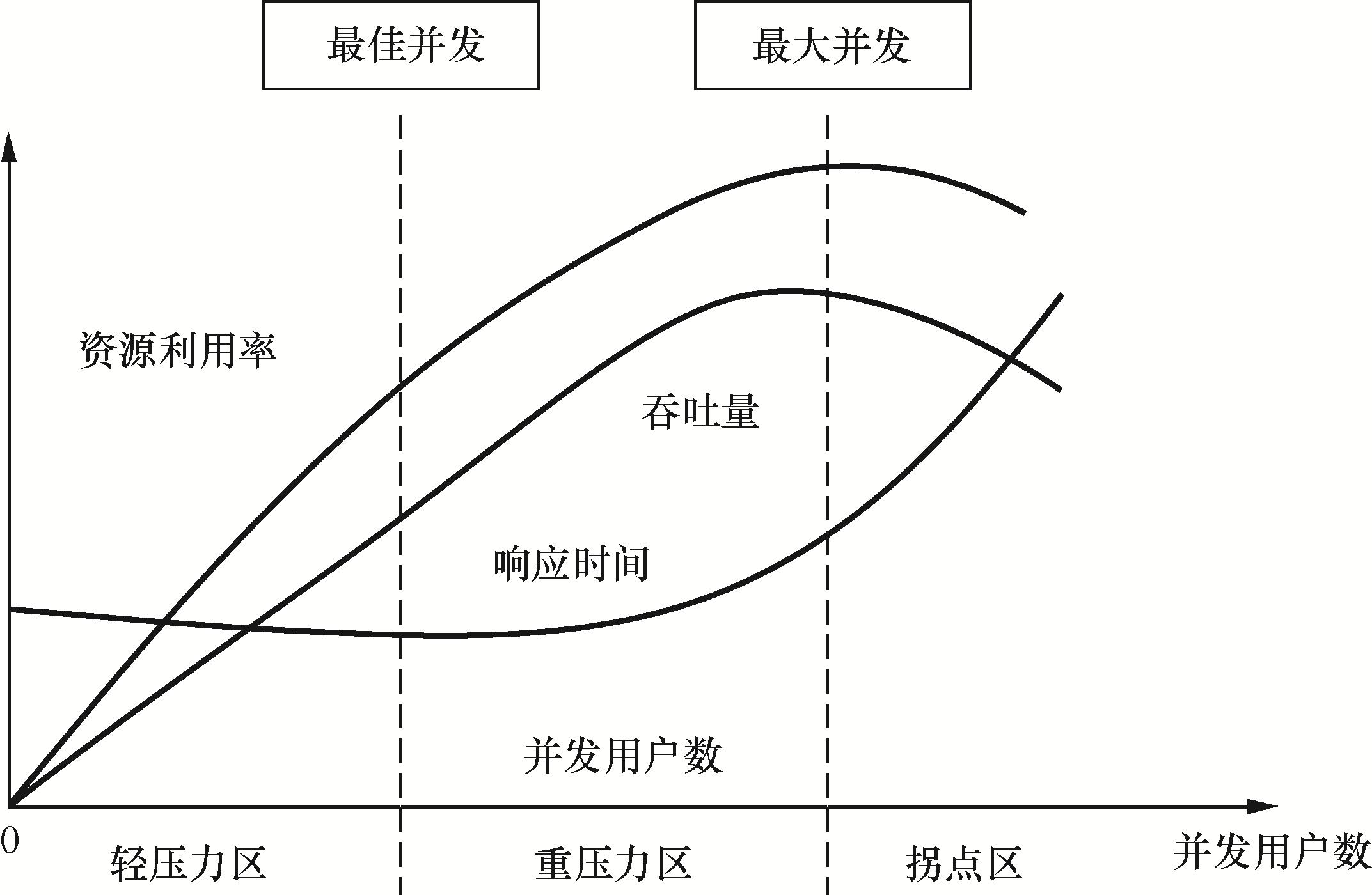
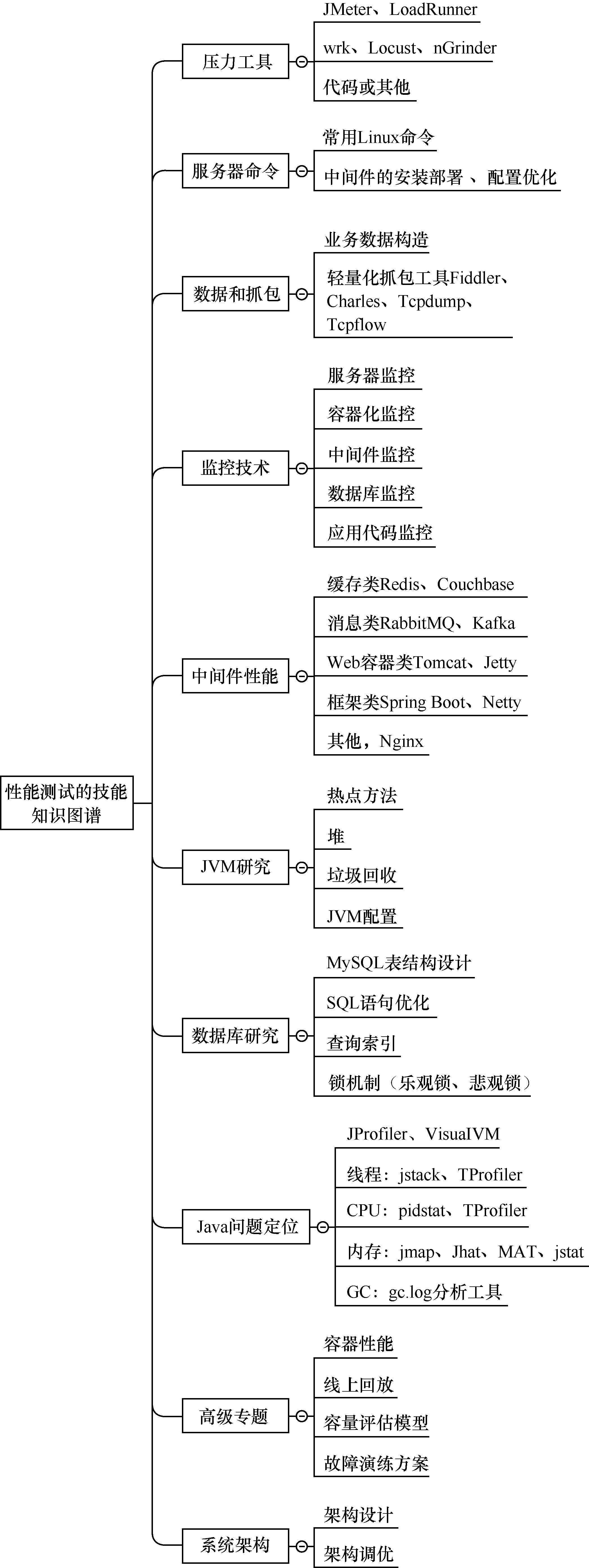
处理秒杀的指导思路
秒杀的核心问题就是极高并发处理,由于系统要在瞬时承受平时数十倍甚至上百倍的流量,这往往超出系统上限,因此处理秒杀的核心思路是流控和性能优化。
流控
1. 请求流控
尽可能在上游拦截和限制请求,限制流入后端的量,保证后端系统正常。
因为无论多少人参与秒杀,实际成交往往是有限的,而且远小于参加秒杀的人数,因此可以通过前端系统进行拦截,限制最终流入系统的请求数量,来保证系统正常进行。
2.客户端流控
在客户端进行访问限制,较为合适的做法是屏蔽用户高频请求,比如在网页中设置5s一次访问限制,可以防止用户过度刷接口。
这种做法较为简单,用户体验也尚可,可以拦截大部分小白用户的异常访问,比如狂刷F5。关键是要明确告知用户,如果像一些抢购系统那样假装提交一个排队页面但又不回应任何请求,就是赤裸裸的欺骗了。
3. Web端流控
对客户端,特别是页面端的限流,对稍有编程知识或者网络基础的用户而言没有作用(可以简单修改JS或者模拟请求),因此服务端流控是必要的。 服务端限流的配置方法有很多种,现在的主流Web服务器一般都支持配置访问限制,可以通过配置实现简单的流控。
但是这种限制一般都在协议层。如果要实现更为精细的访问限制(根据业务逻辑限流),可以在后端服务器上,对不同业务实现访问限制。 常见做法是可以通过在内存或缓存服务中加入请求访问信息,来实现访问量限制。
4.后端系统流控
上述的流控做法只能限制用户异常访问,如果正常访问的用户数量很多,就有后端系统压力过大甚至异常宕机的可能,因此需要后端系统流量控制。
对于后端系统的访问限制可以通过异步处理、消息队列、并发限制等方式实现。核心思路是保证后端系统的压力维持在可以正常处理的水平。 对于超过系统负载的请求,可以选择直接拒绝,以此来对系统进行保护,保证在极限压力的情况下,系统有合理范围内的处理能力。
系统架构优化
除了流控之外,提高系统的处理能力也是非常重要的,通过系统设计和架构优化,可以提高系统的吞吐量和抗压能力。 关于通用系统性能的提升,已经超出本节的范围,这里只会提几点和秒杀相关的优化。
- 读取加速:在秒杀活动中,数据需求一般都是读多写少。20万人抢2000个商品,最后提交的订单最多也就2000个,但是在秒杀过程中,这20万人会一直产生大量的读取请求。因此可以使用缓存服务对用户请求进行缓存优化,把一些高频访问的内容放到缓存中去。对于更大规模的系统,可以通过静态文件分离、CDN 服务等把用户请求分散到外围设施中去,以此来分担系统压力。
- 异步处理和排队:通过消息队列和异步调用的方式可以实现接口异步处理,快速响应用户请求,在后端有较为充足的时间来处理实际的用户操作,提高对用户请求的响应速度,从而提升用户体验。通过消息队列还可以隔离前端的压力,实现排队系统,在涌入大量压力的情况下保证系统可以按照正常速率来处理请求,不会被流量压垮。
- 无状态服务设计:相对于有状态服务,无状态服务更容易进行扩展,实现无状态化的服务可以在秒杀活动前进行快速扩容。而云化的服务更是有着先天的扩容优势,一般都可以实现分钟级别的资源扩容。
系统扩容
这项内容是在云计算环境下才成为可能,相对于传统的 IT 行业,云计算提供了快速的系统交付能力(min VS. day),因此可以做到按需分配,在业务需要时实现资源的并行扩展。
对一次成功的秒杀活动来说,无论如何限流,如何优化系统,最终产生数倍于正常请求的压力是很正常的。 因此临时性的系统扩容必不可少,系统扩容包括以下3个方面。
- 增加系统规格:可以预先增加系统容量,比如提高系统带宽、购买更多流量等。
- 服务扩展:无状态服务+负载均衡可以直接进行水平扩展,有状态的服务则需要进行较为复杂的垂直扩展,增大实例规格。
- 后端系统扩容:缓存服务和数据库服务都可以进行容量扩展。
以较流行的开源Go语言框架chi为例。
- compress.go:对HTTP的响应体进行压缩处理。
- heartbeat.go:设置一个特殊的路由,如/ping、/healthcheck,用来给负载均衡一类的前置服务进行探活。
- logger.go:打印请求处理处理日志,例如请求处理时间、请求路由。
- profiler.go:挂载pprof需要的路由,如/pprof、/pprof/trace到系统中。
- realip.go:从请求头中读取X-Forwarded-For和X-Real-IP,将http.Request中的RemoteAddr修改为得到的RealIP。
- requestid.go:为本次请求生成单独的requestid,可一路透传,用来生成分布式调用链路,也可用于在日志中串连单次请求的所有逻辑。
- timeout.go:用context.Timeout 设置超时时间,并将其通过http.Request一路透传下去。
- throttler.go:通过定长大小的channel存储token,并通过这些token对接口进行限流。
常见的流量限制手段
流量限制的手段有很多,最常见的有漏桶和令牌桶两种。
- 漏桶是指我们有一个一直装满了水的桶,每隔固定的一段时间即向外漏一滴水。如果你接到了这滴水,那么你就可以继续服务请求,如果没有接到,那么就需要等待下一滴水。
- 令牌桶则是指匀速向桶中添加令牌,服务请求时需要从桶中获取令牌,令牌的数目可以按照需要消耗的资源进行相应的调整。如果没有令牌,可以选择等待,或者放弃。
这两种方法看起来很像,不过还是有区别的。漏桶流出的速率固定,而令牌桶只要在桶中有令牌,那就可以拿,如图5-12所示。也就是说,令牌桶是允许一定程度的并发的,例如,同一个时刻,有100个用户请求,只要令牌桶中有100个令牌,那么这100个请求就全都会放过去。令牌桶在桶中没有令牌的情况下也会退化为漏桶。
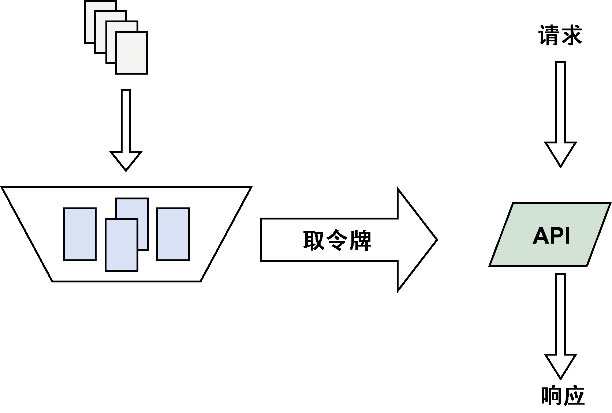
实际应用中令牌桶应用较为广泛,开源界流行的限流器大多数都是基于令牌桶思想的,并且在此基础上进行了一定程度的扩充,比如github.com/juju/ratelimit提供了几种不同特色的令牌桶填充方式:
func NewBucket(fillInterval time.Duration, capacity int64) *Bucket
默认的令牌桶,fillInterval指每过多长时间向桶里放一个令牌,capacity是桶的容量,超过桶容量的部分会被直接丢弃。桶初始是满的。
func NewBucketWithQuantum(fillInterval time.Duration, capacity, quantum int64) *Bucket
和普通的NewBucket()的区别是,每次向桶中放令牌时,是放quantum个令牌,而不是一个令牌。
func NewBucketWithRate(rate float64, capacity int64) *Bucket
这个就有点特殊了,会按照提供的比例,每秒钟填充令牌数。例如,capacity是100,而rate是0.1,那么每秒会填充10个令牌。
从桶中获取令牌也提供了几个API:
func (tb *Bucket) Take(count int64) time.Duration {}
func (tb *Bucket) TakeAvailable(count int64) int64 {}
func (tb *Bucket) TakeMaxDuration(count int64, maxWait time.Duration) (
time.Duration, bool,
) {}
func (tb *Bucket) Wait(count int64) {}
func (tb *Bucket) WaitMaxDuration(count int64, maxWait time.Duration) bool {}
名称和功能都比较直观,这里就不再赘述了。 相比于开源界更为有名的谷歌公司的Java工具库Guava中提供的限流器,这个库不支持令牌桶预热,且无法修改初始的令牌容量,所以可能个别极端情况下的需求无法满足。 但在明白令牌桶的基本原理之后,如果没办法满足需求,相信你也可以很快对其进行修改以支持自己的业务场景。
原理
从功能上来看,令牌桶模型就是对全局计数的加减法操作过程,但使用计数需要我们自己加读写锁,有小小的思想负担。 如果我们对Go语言已经比较熟悉的话,很容易想到可以用带有缓冲的通道来完成简单的加令牌/取令牌操作:
var tokenBucket = make(chan struct{}, capacity)
每过一段时间向tokenBucket 中添加令牌,如果桶已经满了,那么直接放弃:
fillToken := func() {
ticker := time.NewTicker(fillInterval)
for {
select {
case <-ticker.C:
select {
case tokenBucket <- struct{}{}:
default:
}
fmt.Println("current token cnt:", len(tokenBucket), time.Now())
}
}
把代码组合起来:
package main
import (
"fmt"
"time"
)
func main() {
var fillInterval = time.Millisecond * 10
var capacity = 100
var tokenBucket = make(chan struct{}, capacity)
fillToken := func() {
ticker := time.NewTicker(fillInterval)
for {
select {
case <-ticker.C:
select {
case tokenBucket <- struct{}{}:
default:
}
fmt.Println("current token cnt:", len(tokenBucket), time.Now())
}
}
go fillToken()
time.Sleep(time.Hour)
}
在1秒的时候刚好填满100个,没有太大的偏差。不过这里可以看到,Go的定时器存在大约0.001秒的误差,所以如果令牌桶大小在1000以上的填充可能会有一定的误差。 对一般的服务来说,这一点误差无关紧要。
上面的令牌桶的取令牌操作实现起来也比较简单,为简化问题,我们这里只取一个令牌:
func TakeAvailable(block bool) bool{
var takenResult bool
if block {
select {
case <-tokenBucket:
takenResult = true
}
} else {
select {
case <-tokenBucket:
takenResult = true
default:
takenResult = false
}
}
return takenResult
}
一些公司自己造的限流的轮子就是用上面这种方式来实现的,不过如果开源限流器也如此的话,那我们也没什么可说的了。现实并不是这样的。
我们来思考一下,令牌桶每隔一段固定的时间向桶中放令牌,如果我们记下上一次放令牌的时间为t1,当时的令牌数k1,放令牌的时间间隔为ti,每次向令牌桶中放x个令牌,令牌桶容量为cap。
现在如果有人调用TakeAvailable来取n个令牌,我们将这个时刻记为t2。
在t2时刻,令牌桶中理论上应该有多少个令牌呢?伪代码如下:
cur = k1 + ((t2 - t1)/ti) * x
cur = cur > cap ? cap : cur
我们用两个时间点的时间差,再结合其他参数,理论上在取令牌之前就完全可以知道桶里有多少个令牌了。
那劳心费力地像本小节前面向通道里填充令牌的操作,理论上是没有必要的。
只要在每次Take的时候,再对令牌桶中的令牌数进行简单计算,就可以得到正确的令牌数。
是不是很像惰性求值的感觉?
在得到正确的令牌数之后,再进行实际的Take操作就好,这个Take操作只需要对令牌数进行简单的减法即可,记得加锁以保证并发安全。
github.com/juju/ratelimit这个库就是这样做的。
高并发系统三把利
从大的层面来说,在开发高并发系统时,有三把利器用来保护系统:缓存、降级和限流。其中,缓存是最为重要的一个应对高并发的方式。Redis缓存中间件目前已经成为缓存的事实标准。
微服务Provider实例之间的RPC在Spring Cloud全家桶技术体系中是由Feign基于Ribbon完成的,并由Hystrix组件提供RPC的熔断、回退、限流等保护。
接入层主要完成鉴权、限流、反向代理和负载均衡等功能。 由于在静态资源、登录验证等简单逻辑的处理性能上Nginx和Tomcat不可同日而语(一般在10倍以上),因此接入层基本上都是使用Nginx + Lua扩展作为接入服务器。 另外,为了保证Nginx接入服务器的高可用,会搭建有冗余的接入服务器,然后使用KeepAlived中间件进行高可用监控管理并且虚拟出外部IP,供外部访问。
秒杀系统的架构设计
限流
限流是指通过对某一时间窗口内的请求数进行限制,保持系统的可用性和稳定性,防止因流量暴增而导致系统运行缓慢或宕机,限流的根本目的就是为了保障服务的高可用。 当系统容量达到瓶颈时,我们需要通过限制一部分流量来保护系统,并做到既可以人工执行开关,也支持自动化保护的措施。 限流是比降级更极端的一种保护措施。
限流既可以是在客户端限流,也可以是在服务端限流。 限流的实现方式既要支持 URL以及方法级别的限流,也要支持基于 QPS(每秒查询率)和线程的限流。 例如,我们的系统最高支持1万QPS时,可以设置8000QPS来进行限流保护。
秒杀系统的架构设计思想主要有:
- 缓存: 把部分业务逻辑迁移到内存的缓存或者Redis中,从而极大地提高并发读效率。
- 削峰: 秒杀开始的一瞬间,会有大量用户冲进来,所以在开始时会有一个瞬间流量峰值。如何使瞬间的流量峰值变得更平缓,是成功设计秒杀系统的关键。要实现流量的削峰填谷,一般的方法是采用缓存和MQ中间件。
- 异步: 将同步业务设计成异步处理的任务,以提高网站的整体可用性。
- 限流: 由于活动库存量一般都很少,只有少部分用户才能秒杀成功,所以需要限制大部分用户流量,只准少量用户流量进入后端服务器。
总结
秒杀系统是学习“三高”(高性能、高并发、高可用)的一个非常好的例子,具有读多写少等特性。 为了保证系统的高可用,使用避免单点措施(应用服务、数据库、缓存等)可保证服务的稳定性; 对于高并发读,引入Redis缓存可避免流量直接穿透到数据库,同时,引入消息中间件则可对流量进行削峰。 除了技术上的设计,业务方法上使用答题/验证码、分时分段以及禁用秒杀按钮等措施,可将请求流量尽量拦截在上游。 最后,在最坏的情况下,使用系统降级、限流、拒绝服务等错误,可起到保护系统以防宕机的作用。 为了让读者能轻松学习,本书仅提供了一个简单的例子,真实的秒杀系统架构设计更复杂,业务逻辑更烦琐,读者可在此基础上进一步完善。
微服务框架
什么是侵入式微服务架构呢?这里以微服务框架Spring Cloud为例进行说明。 Spring Cloud侵入式微服务框架如图5-2所示。 SpringCloud是一个面向分布式系统构建的技术体系,为开发人员提供了构建分布式系统所需的核心和外围组件,基于Spring Framework和Spring Boot技术框架,能够实现“开箱即用”,快速搭建微服务架构所需的功能。
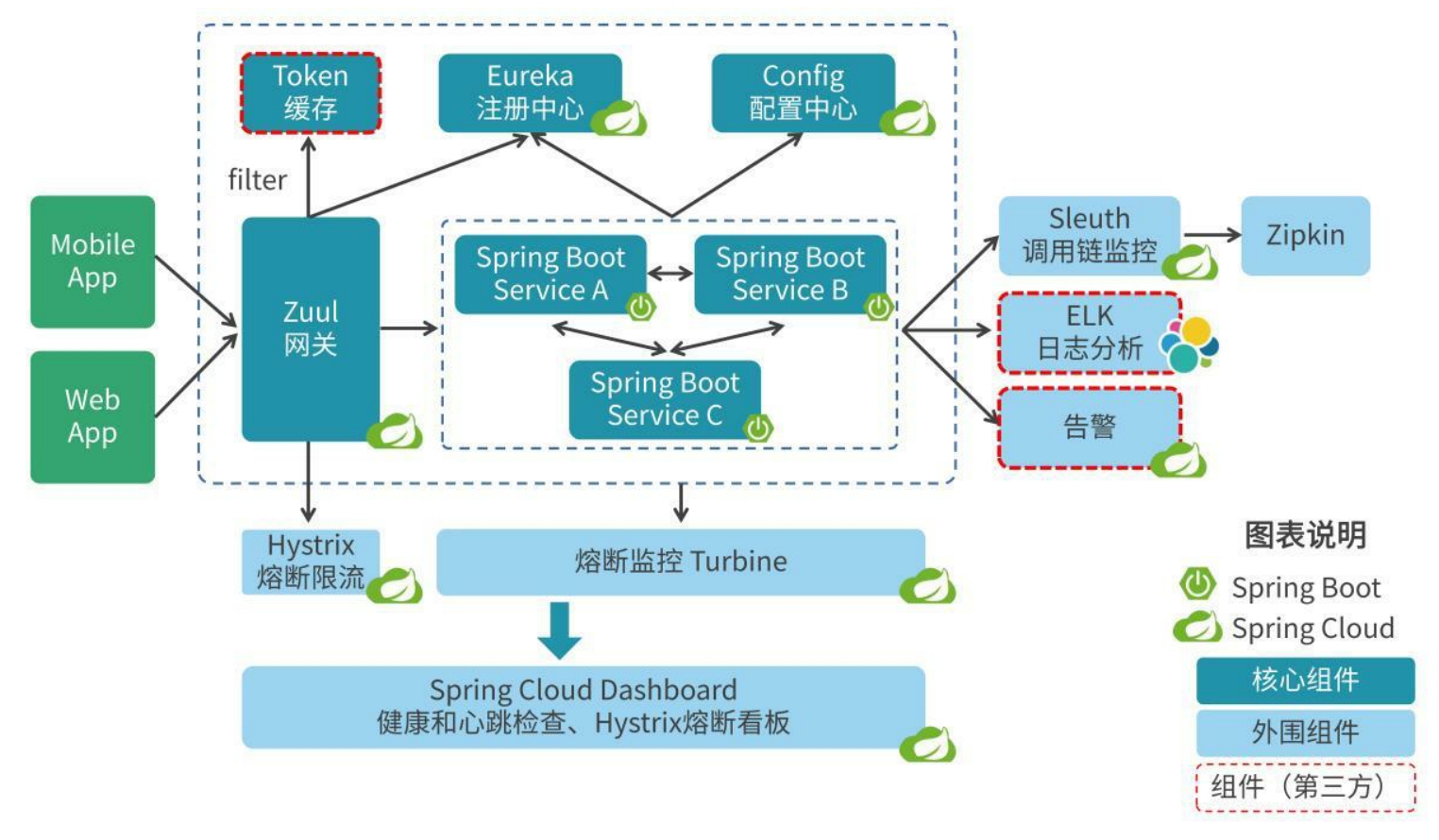
在微服务框架中使用Eureka Server作为服务注册中心,在微服务单元上配置使用Eureka Client向注册中心发起注册。 这样就会带来一个问题,在旧代码或者非Java代码(比如Python)中使用Spring Cloud微服务框架时,需要对旧代码及非Java代码进行微服务化的改造。 Spring Cloud侵入式微服务框架的主要组件模块的功能如下。
- 网关Zuul:服务路由、负载均衡、访问安全控制、熔断限流。
- 注册中心Eureka:服务注册和发现。
- 配置中心Config:应用环境配置。
- 微服务Spring Boot:应用服务开发。
- 流量监控Turbine:流量监控、熔断限流监控。
- Spring Cloud Dashboard:应用健康状态、心跳检查,熔断限流看板。
- 调用链监控Sleuth:通过日志跟踪调用链。
- 日志分析ELK:日志分析。
- 告警:健康和熔断告警。
什么是非侵入式微服务框架呢?就好比给一个普通的摩托车加上一个sidecar,在不影响摩托车原有内部构造的前提下,增加新的功能。 原来的业务继续跑在单独的进程里,与微服务相关的功能(服务治理、流量控制、熔断等)放到Sidecar里并注入到同一个容器里。
Hystrix断路器:提供服务熔断和限流功能。 该框架的作用在于通过控制那些访问远程系统、服务和第三方库的节点,对延迟和故障现象提供更强大的容错能力。
限流器
这里引出了限流器(Throttle)的概念,限流器的作用是在线程执行的并发度达到阈值时让后续的线程处于阻塞等待。 这是SpringTaskExecutor设计上的一个亮点,基本思想如图11-2所示。
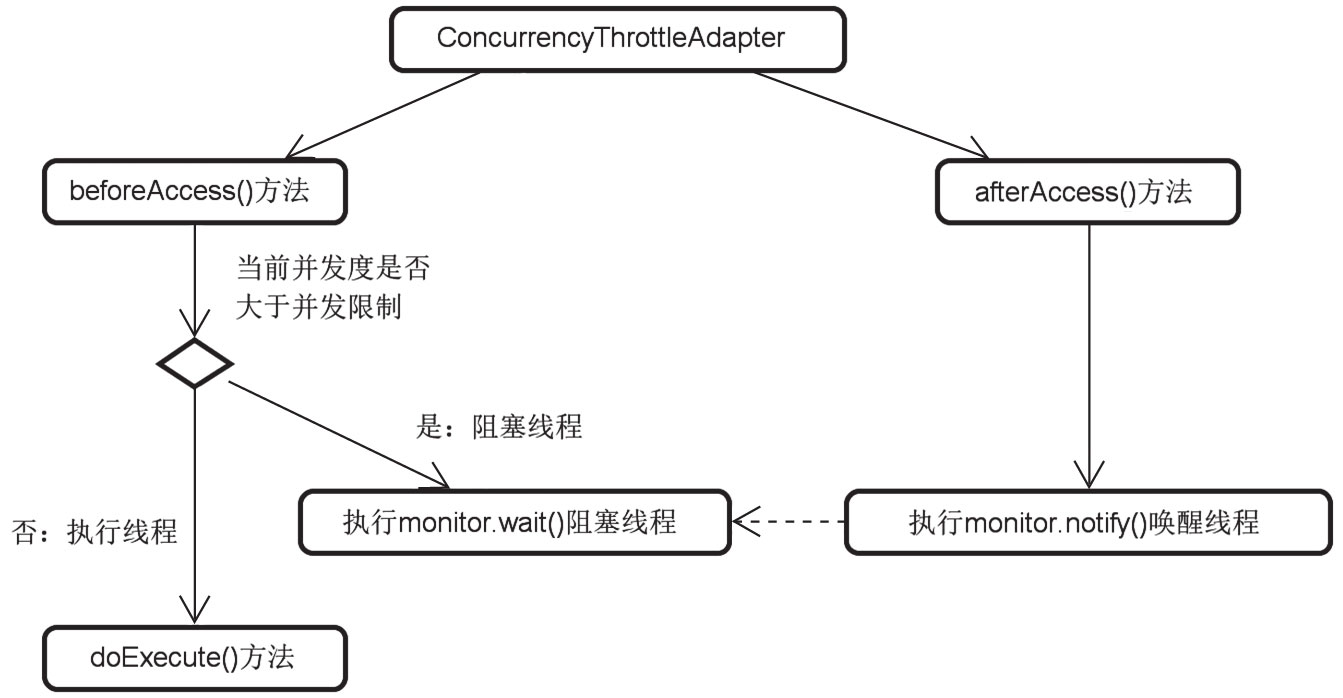
通过图11-2,我们不难看出限流器在线程执行之前进行了对并发限制的判断,如果需要限流就阻塞线程。而一旦任务执行完成,就会唤醒正在等待的线程继续执行任务。
Q: AsyncListenableTaskExecutor中的限流器是如何运作的?
Spring的AsyncListenableTaskExecutor任务执行器引入了限流器的设计理念。 作为一种针对线程的限流机制,限流器的作用是在线程执行的并发度达到阈值时让后续的线程处于阻塞等待状态。 限流器是Spring TaskExecutor设计上的一个亮点,也是开发人员在面试中经常会碰到的话题。 而且,这种限流思想对于开发人员自己设计类似的应用场景的解决方案也有很高的参考价值。
限流降级
在互联网应用场景下,用户的访问并不总是均匀平稳的,时常会出现瞬时的高峰,比如活动期间。 分布式应用服务需要提供限流功能,时刻感知流量的变化,并做出相应调整。限流的策略可分为限制访问的绝对数量和控制流速(整流)。 整流的算法有令牌桶算法,限制总数可通过设置规则来实现。
降级是指某个服务被调低级别后,本服务的消费者在调用时即刻返回失败,这样服务实例将不会被调用。 当然,也可以设置一个默认返回值。降级的规则支持用户灵活配置。
平台高可用
平台高可用是指计算平台本身的高可用,能够不间断地为用户提供计算产品的自助操作,如门户网站访问、云主机购买、开机、关机、云硬盘挂载等。
平台高可用设计要点如下。
- 避免单点故障:可部署跨可用区跨地域的多节点结合负载均衡技术实现同城灾备、异地灾备,做到自动故障切换。
- 应用的高可用性:从平台角度,提供服务治理(服务降级、限流),容错自愈的能力,提高服务可用性; 提供系统监控(CPU、内存、磁盘),链路监控,日志监控等能力,便于故障追踪、自动预警; 提供数据分片、读写分离等手段有效应对大规模数据量,实现数据库的无缝扩容。
- 分布式架构下的可伸缩设计:既支持基于服务器硬件能力升配/降配的垂直伸缩,也支持服务器数量增减的水平伸缩。
微服务网关
微服务网关(PAFA-Cloud Router)是PAFA-Cloud微服务框架的基础组件之一。 从功能上看,它是微服务群的集中出口,负责外部对微服务请求的路由转发、用户认证、服务安全、限流等非业务性功能。
API网关技术架构
API网关的主要目的就是将后端的服务API进行暴露和聚合,为内外部调用方提供一个统一入口,从而使得后端的服务API对外可用。 在此基础上,API网关还提供了不同层次的功能,可以划分为核心层、增强层、安全层以及监控层等,如图8.28所示。
- 核心层包括请求验证、路由转发、负载均衡等,提供请求转发功能;
- 增强层包括请求转换、协议转换等,提供增强API的功能;
- 安全层包括认证、鉴权、限流、访问控制等,保证请求安全性;
- 监控层则包括调用统计、异常告警、日志服务等,提供对API的调用情况进行监控与分析的能力。
目前网关的主流有Zuul、Kong、Spring Cloud Gateway。
Zuul是Netflix开源的网关组件,是从设备和网站到Netflix流应用程序后端的所有请求的前门。 作为边缘服务应用程序,Zuul旨在实现动态路由、监控、弹性和安全性。
Kong是一个云原生、快速、可扩展和分布式的API网关。更确切地说,Kong是一个在Nginx中运行的Lua应用程序,通过Lua-nginx模块实现。 Kong 与 OpenResty 一起发布, OpenResty是Nginx的一组扩展功能模块,包含了Lua-nginx模块。
Spring Cloud Gateway提供了一个建立在Spring生态之上的API网关,包括Spring 5、Spring Boot 2和Project Reactor。 它旨在提供一种简单而有效的方式来路由到API,并提供安全性、指标监控和弹性等扩展功能。
微服务网关管理
微服务网关管理目前支持定制路由、服务/接口屏蔽、黑名单管理、限流策略管理、运行时信息查询、配置管理等。
- 定制路由:支持用户自定义的路由规则,实现智能路由。
- 服务/接口屏蔽:支持根据业务需求线上动态地屏蔽服务或接口。
- 黑名单管理:支持线上动态调整基于IP或者用户的黑名单。
- 限流策略管理:支持线上动态调整限流策略,定制的流量策略可用于单个接口、单个服务、多服务或全局。
- 运行时信息查询:可提供Router各实例的不同层面的运行信息查询。
- 配置管理:可以提供Router启动或运行配置的可视化管理。
服务网关:服务网关是服务调用的唯一入口,可以在这个组件是实现用户鉴权、动态路由、灰度发布、A/B测试、负载限流等功能。
开源组件Zuul
开源组件Zuul可提供如下功能:
- 动态路由。服务请求被动态地路由到后端服务集群。虽然API网关后端是复杂的分布式微服务网状结构,但是外部系统从API网关来看就像是一个整体服务,API网关屏蔽了后端服务的复杂性。
- 限流和容错。为各种类型的业务请求分配容量,如请求量超过阈值则丢弃外部请求,启动限流,保护后台服务不被大流量冲垮,进而避免雪崩效应;当内部服务出现故障时,直接在边界返回响应,集中做容错处理,而不将请求再转发到内部集群,保证有良好的用户体验。
- 身份认证和安全性控制。对每个外部请求进行身份认证,拒绝非法请求,还可通过访问模式分析,阻止外部的数据抓取(爬虫)。
- 监控。API网关可以收集各种数据并进行统计,为后台服务优化提供数据支持。
- 访问日志。API网关可以收集访问日志,如哪个服务被访问?处理过程是否异常?访问的总时长是多少?哪一段访问过程耗时最多等。通过分析日志内容,对后台系统做进一步优化。
断路器
通常情况下,微服务之间存在错综复杂的依赖关系,一次请求可能会依赖多个后端服务,这些微服务可能发生故障、延迟等情况,一旦某个服务产生延迟,可能会在短时间内耗尽系统资源,将整个系统拖垮。 因此需要对处于故障状态的服务进行隔离和容错,否则会导致雪崩效应,产生灾难性后果。
Spring Cloud Hystrix可以很好地解决上述问题,它通过熔断模式、隔离模式、回退(fallback)和限流等机制对服务进行弹性容错保护,保证系统的稳定性。
- 熔断模式。熔断模式原理类似于电路熔断器,当电路发生短路时,熔断器熔断,保护电路避免遭受灾难性损失。当服务异常或者大量延时,即满足熔断条件时服务调用方会主动启动熔断,执行fallback逻辑直接返回,不会继续调用服务进一步拖垮系统。熔断器默认配置服务调用错误率阈值为50%,超过阈值将自动启动熔断模式。服务隔离一段时间以后,熔断器会进入半熔断状态,即允许少量请求进行尝试,如果仍然调用失败则回到熔断状态,如果调用成功则关闭熔断模式。
- 隔离模式。Hystrix默认采用线程隔离,不同的服务使用不同的线程池,彼此之间不受影响,当一个服务出现故障时将耗尽它的线程池资源,其他的服务正常运行而不受影响,以达到隔离效果,避免因某一个服务而影响全局。Hystrix会在某个服务连续调用N次不响应的情况下,立即通知调用端调用失败,避免调用端持续等待而影响了整体服务。Hystrix间隔一段时间会再次检查此服务,如果服务恢复将继续提供服务。
- 回退。回退机制其实是一种服务故障时的容错方式,原理类似Java中的异常处理。只需要继承HystixCommand并重写getFallBack()方法,在此方法中编写处理逻辑,比如可以直接报异常(快速失败),可以返回空值或默认值,也可以返回备份数据等。当服务调用出现异常时会转向执行getFallBack()。
- 限流。是指限制服务的并发访问量,超出限制的请求时拒绝并回退,防止后台服务被“冲垮”。
统一的接入服务接口采用Spring Cloud的Zuul组件,实现内外有别的微服务调用。 该组件也实现了服务路由功能。采用Spring CloudNetflix来实现服务的限流和降级。 为了实现服务的高可用,保证服务的容错和负载均衡,可采用客户端负载均衡(Ribbon)来实现。
Spring Cloud Netflix的Hystrix熔断器组件,具有容错管理工具,旨在通过熔断机制控制服务和第三方库的节点,从而对延迟和故障提供更强大的容错能力。 为了保证核心服务的稳定性,可采用Spring Cloud Netflix的Hystrix组件来实现服务的容错、限流和降级等功能。
云原生时代的流量管理
Istio的流量管理能力主要体现在以下三个方面。
- 动态路由和流量转移:基本路由设置,按比例流量切分等。
- 弹性能力:超时、重试、熔断、限流。
- 流量调试:故障注入、流量镜像。
流量管控
当微服务数量越来越多时,需要一种服务治理机制对所有微服务进行统一管控,保障微服务的正常运行。 微服务治理覆盖整个生命周期,从微服务建模、开发、测试、审批、发布到运行时的管理及下线。 而微服务中的服务治理主要是指运行时的治理,除了前面所讲的配置、健康检查等,还包括断融、限流、降级等流量管控。
- 断融:是指一个远程微服务调用在连续失败次数超过指定的阈值后的一段时间内会拒绝其他调用。例如,Spring Cloud的Hystrix就为保护服务依赖提供了熔断机制的开源库。
- 限流:通过全链路的压力测试,应该能够知道整个应用的支撑能力,因此制定了限流策略,保证应用处理请求处于其支撑能力范围内,超出其支撑能力范围的请求处理可被拒绝。例如,使用下单服务时弹出对话框,显示“系统忙,请重试”,这并不代表下单应用停止服务了,而是限流策略起到了作用。
- 降级:是指当发现整个应用服务负载过高时,可以选择降级某些功能来保证最重要的交易流程正常工作,以及最重要的资源全部用于保证最核心的流程。假设服务A依赖服务B和服务C,而服务B和服务C可能又依赖其他服务,继续下去会使得调用链路过长。如果在服务A后续的链路上某个或某几个被调用的微服务不可用或者延迟较高,则会导致调用服务A的请求被堵住。被堵住的请求会占用系统的线程、I/O等资源,当该类请求越来越多时,占用的资源就会越来越多,从而导致系统出现瓶颈,造成其他请求同样不可用,最终导致业务应用崩溃,所以应当及时将服务A降级。
在分布式微服务应用中,当一个微服务企图调用另一个微服务发送同步请求时,会面临着局部故障的风险。局部故障会导致客户端一直处于等待响应状态,从而造成访问阻塞,进而影响整个应用的可用性。当一个微服务调用另一个微服务超时时,应该及时返回而非阻塞在那里,避免影响其他微服务。当一个微服务发现被调用的微服务因过于繁忙、线程池满、连接池满或总是出错时,应该及时熔断,防止下一个微服务错误或繁忙导致本服务不正常,进而逐渐往前传导导致整个应用崩溃。
API网关的功能包括:路由、负载均衡、统一认证和鉴权、监控、日志、限流降级等。 API网关的缺点是增加了部署和运维的复杂度,同时需要适配大量接口,导致难以维护。 另外,因为通过API网关会在调用链增加一跳,所以会导致性能的下降。
在API网关中,所有的扩展都基于插件来实现,其中包括安全认证类插件、流量控制类插件、日志监控类插件、转换类插件等。 API和插件之间是多对多的关系,即一个API可以被作用于多个插件,同时一个插件也可以被应用在多个API上。 插件本身类似于AOP横切,对服务请求消息的输入和输出进行拦截,在拦截到消息后进行相关的安全处理或管控处理。
公有云容器化指南:腾讯云TKE实战与应用
服务网关的功能
- 认证、鉴权
- 安全
- 金丝雀测试(灰度)
- 动态路由
- 限流
- 聚合
- Spring Cloud Gateway作为Spring Cloud生态系统中的网关,目标是替代Netflix Zuul,不仅提供统一的路由方式,还以基于Filer链的方式提供安全、监控/埋点、限流功能。
熔断器(Hystrix)
在分布式架构中,当某个服务单元发生故障(类似电器发生短路)时,会通过断路器的故障监控(类似熔断保险丝)向调用方返回一个错误响应。 这样就不会因调用线程故障让服务被长时间占用,避免故障在分布式系统中蔓延。
Hystrix负责监控服务之间的调用情况,连续多次失败会开启熔断保护,其主要工作流程如下。
- 检查缓存
- 检查circuit breaker状态
- 运行相应指令
- 记录数据,计算失败比率
- Spring Cloud Hystrix在微服务治理中扮演着重要角色,通过对它做二次开发,可以实现更加灵活的故障隔离、降级和熔断策略,满足API网关等服务的特殊业务需求。
进程内的故障隔离仅是服务治理的一方面,另一方面,在应用混部的主机上,应用间应该互相隔离,避免进程互抢资源。比如,一定要避免离线应用失控,占用大量CPU资源,使得同主机的在线应用受影响。通过Kubernetes限制容器运行时的资源配额(以CPU和内存限制为主),可以实现进程间的故障和异常隔离。Kubernetes提供的集群容错、高可用、进程隔离配合SpringCloud Hystrix提供的故障隔离和熔断,能够很好地实践“Design for Failure”设计哲学。
Istio功能说明
Istio主要有以下4个特点。
- Istio适用于容器环境,特别是和Kubernetes结合。
- 在对业务进行微服务改造时,Istio能够帮助微服务之间建立连接,形成mesh,且不需要对业务代码做任何改动。
- 进行数据流程交互时,会先经过Istio,实现HTTP、TCP、WebSocket和GRPC流量自动负载均衡,对集群入口和出口的流量进行自动度量指标、跟踪和日志记录。在基于身份验证和授权的集群中实现安全的服务间通信。
- Istio proxy层能提供基础架构能力,例如负载均衡、服务发现、服务监控、故障恢复、故障测量、限流限速、A/B测试、灰度发布等。
Java EE互联网轻量级框架整合开发:SSM+Redis+Spring微服务
可用性是客户对系统的一个基本要求,如果这一要求得不到保证,会极大地影响用户的忠诚度。 而实际上任何系统都有其服务上限,高并发引发过多的请求会使得服务趋于不稳定,甚至崩溃。 为了保证系统的可用性,一般来说我们可以从这几个方面进行考虑:网关过滤、限流和降级服务、隔离术、断路器保护服务。
限流和降级服务
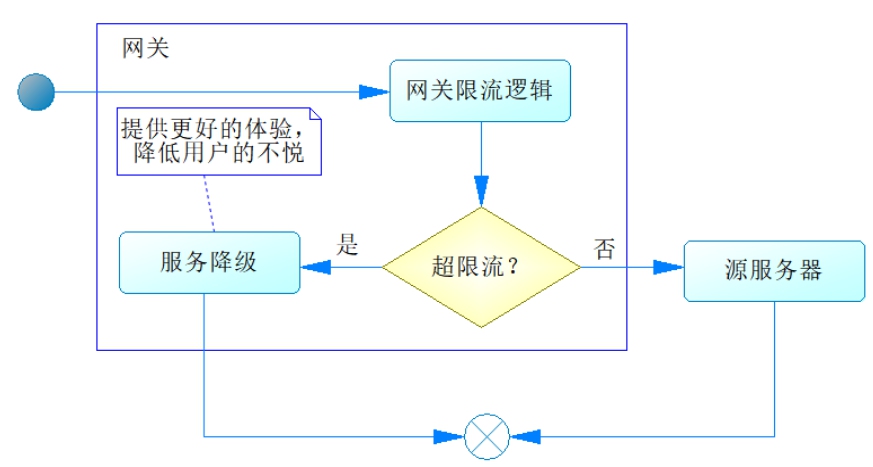
尽管可以采取网关过滤的手段,有时候我们得到的请求可能还是太多,于是需要新的办法来保证服务器不被压垮,这个时候可以考虑使用服务限流和服务降级的办法。 在学习Resilience4j的过程中,我们也谈到了限速器,通过它可以限制路由到源服务器的流量,从而保证源服务器不被压垮。 只是在进行限流的时候,对于超量的请求,也应该使用降级服务来改善用户的体验。使用Resilience4j的限速器请求限流的过程如图28-8所示。
图28-8中的服务降级提示用户的界面应尽量友好,比如提示“小二正忙”等,这样就能降低用户的不悦感,提高他们对网站的忠诚度。
隔离术
隔离术是处理高并发的一种常用方法,它可以使得一些服务被隔离在某个范围之内,即使这个范围内的服务出现了故障,也不会危及整个系统,从而保护整个服务,而隔离之后的服务,可以单独进行优化和设计。
严格来说,之前谈到的动静分离和热点数据优化都可以归结为隔离术,此外还存在集群隔离、线程隔离、机房隔离和爬虫隔离等。 集群、机房等隔离是设计师需要考虑的,在开发中我们最常用到的是线程隔离。 而在介绍Spring Cloud时,本书也分别讲述了Hystrix和Resilience4j的舱壁隔离(Bulkhead),通过它们我们可以将特定的服务在特定的线程池内运行,从而完成隔离。
断路器
在介绍Spring Cloud时,我们也讲述了Hystrix和Resilience4j的断路器,善用断路器可以控制各个服务之间的调用流量,同时可以避免服务依赖导致服务雪崩,从而保证服务调用在安全稳定的环境下运行。
设计高可靠服务
服务可用性对应用可靠性的影响
设计能够抵御外部依赖故障的服务
重试、限流、断路器、健康检查和缓存可以减少服务间的通信问题
在不同的服务间采用安全的通信标
限流和降级
限流算法简单,当在双十一这种特殊场景,会看到毛刺现象,需要一种更平滑的限流算法。
因为此方案在实际应用中所暴露出的问题,所以有了限流平台Sentinel的出现。 Sentinel平台正如它英文的意思“哨兵”一样,为整个服务化体系的稳定运行行使着警戒任务,是对资源调用的控制平台,主要涵盖了授权、限流、降级、调用统计监控四大功能模块:
- 授权——通过配置白名单与黑名单的方式对HSF的接口和方法进行调用权限的控制;
- 限流——对特定资源进行调用的保护,防止资源的过度调用;
- 降级——判断依赖的资源的响应情况,当依赖的资源响应时间过长时进行自动降级,并且在指定的时间后自动恢复调用;
- 监控——提供了全面的运行状态监控,实时监控资源的调用情况(QPS、响应时间、限流降级等信息)。
Sentinel平台有两个基础概念:资源和策略,对特定的资源采取不同的控制策略,起到保障应用稳定性的作用。 Sentinel提供了多个默认切入点,比如服务调用时,数据库、缓存等资源访问时,覆盖了大部分应用场景,保证对应用的低侵入性;同时也支持硬编码或者自定义AOP的方式来支持特定的使用需求。
Sentinel平台的架构如图8-4所示,需要通过Sentinel实现限流功能的应用中都嵌入了Sentinel客户端,通过Sentinel客户端中提供对服务调用和各资源访问缺省实现的切入点,使得应用方完全不需要对要实现限流的服务或资源进行单独的AOP配置和实现,同时不仅可以限制自己的应用调用别的应用,也可以限制别的应用调用对用我的应用。 通过这些资源埋点实时计算当前服务的QPS,也可通过现有的监控系统获取到应用所在服务器的相关系统监控指标,用于限流规则设置中的阀值比对。
Zuul的作用
Zuul是Netflix公司开发的一种网关服务,它最核心的功能是过滤器,通过Zuul可以实现如下功能。
- 动态路由:所谓动态,就是请求的地址不是一成不变的,可以根据后端逻辑的需要对请求地址进行修改,实现一个地址的转变。
- 监控:可以通过监控请求信息进行流量统计和接口响应时间计算;对于项目安全也有帮助,可以分析请求信息是否带有恶意的脚本等。
- 处理静态文件资源:如果业务中包含很多静态资源,如视频、图片、音频等处理起来耗时较大的媒介资源,对于整个项目的性能来说是不好的,因此可以在项目最外层将其进行处理。
- 限流:通过限流的粒度对不同对象进行限制。针对细粒度,有以下不同的对象。
- ① user:认证用户或匿名,针对某个用户粒度进行限流。
- ② origin:客户机的IP,针对请求客户机的IP进行限流。
- ③ url:特定url,针对请求的URL粒度进行限流。
- ④ serviceId:特定服务,针对某个服务的ID粒度进行限流。
限流机制
限流算法
限流的时候,如果要准确地控制TPS,简单的做法是维护一个单位时间内的计数器,如判断单位时间已经过去,则将计数器重置零。 此做法被认为没有很好地处理单位时间的边界,比如在前一秒的最后一毫秒里和下一秒的第一毫秒都触发了最大的请求数,也就是在两毫秒内发生了两倍的TPS。 常用的平滑限流算法有两种:漏桶算法和令牌桶算法。
漏桶算法
思路很简单,水(请求)先进入到漏桶里,漏桶以一定的速度出水(接口有响应速率),当水流入速度过大会直接溢出(访问频率超过接口响应速率),然后就拒绝请求,可以看出漏桶算法能强行限制数据的传输速率。
这里有两个变量,一个是桶的大小,即流量突发增多时可以存多少的水(burst),另一个是水桶漏洞的大小(rate)。因为漏桶的漏出速率是固定的参数,所以,即使网络中不存在资源冲突(没有发生拥塞),漏桶算法也不能使流突发(burst)到端口速率。因此,漏桶算法对于存在突发特性的流量来说缺乏效率。
令牌桶算法
和漏桶算法效果一样但方向相反,更加容易理解。 随着时间流逝,系统会按恒定时间间隔(如果QPS=100,则间隔是10毫秒)往桶里加入令牌(Token,想象和漏洞漏水相反,有个水龙头在不断的加水),如果桶已经满了就不再加了。 新请求来临时,会各自拿走一个令牌,如果没有令牌可拿了就阻塞或者拒绝服务。
令牌桶算法的另外一个好处是可以方便地改变速度。 一旦需要提高速率,则按需提高放入桶中的令牌的速率。 一般会定时(比如100毫秒)往桶中增加一定数量的令牌,有些变种算法令实时计算应该增加的令牌的数量。
微服务的限流操作和Zset的那些瓜葛
有序集(Zset)类型是Redis中一个非常重要的数据类型,类似于集合类型和哈希类型之间的混合类型。 像Set集合一样,Zset有序集由唯一、非重复的一组元素所组成,从某种意义上说也是一个集合。
虽然Zset内的元素没有排序,但是排序后集合中的所有元素都与一个称为得分的浮点值相关联(这就是Zset类型类似于哈希类型的原因,因为每个元素都映射到一个值)。
微服务(架构图如图2-37所示)日益流行,缓存、降级和限流是保护微服务系统运行稳定性的三大利器。 缓存的目的是提升系统访问速度和增大系统处理的容量,而降级是当服务出现问题或者影响到核心流程的性能时需要暂时被屏蔽掉,待高峰或者问题解决后再打开。 有些场景并不能用缓存和降级来解决,比如稀缺资源、数据库的写操作、频繁的复杂查询,因此需有一种手段来限制这些场景的请求量,这就是限流。 Redis的Zset类型的结构可以实现限流功能。
利用Zset实现限流
限流是对系统的出入流量进行控制,防止大流量出入,从而导致资源不足、系统不稳定。 限流的目的应当是通过对并发访问和请求进行限速或者对一段时间内的请求进行限速来保护系统。 一旦达到限制速率就可以拒绝服务或者让请求的服务等待。
假设我们上线一个服务,而这个服务提供的最大处理能力是1秒服务2000个QPS,遇到高于2000的QPS该如何解决呢?如果不对其限流,后果可想而知。
下面了解一下两种基本的限流算法。
1.滑动窗口限流方式
前两个窗口和后两个窗口分别表示的是第一秒和第二秒,它们的长度相同,表示每一秒接收的请求数量相同,达到了限流的效果。 这种固定窗口限流会出现一些问题。假设限流设置为1秒2000个请求,而在第一秒的最后100毫秒以及第二秒开始的100毫秒都收到2000次请求,就等于在200毫秒的周期中收到4000次请求,并且限流通过。 这样就出现了两倍的配置速率问题。
滑动窗口为固定窗口的改进版,在每个时间片段接收到的请求数量都是相等的,或者不会超过限制数量。接下来我们看一下使用Zset应该如何处理。
- 首先利用Zset类型在value处存放随机字符,而在score部分存储时间戳。
- 每一次请求进来的时候获取限流key值数量,根据当前时间戳和当前时间减去前一秒的时间戳。这样每次获取的都是一秒内的总请求数量。
- 如果没有超过限制,继续处理;如果超过,则等待或者直接返回。
2.令牌桶
令牌桶算法是和漏桶算法效果一样但方向相反的算法,且更加容易理解。 随着时间的流逝,系统会按恒定1/QPS时间间隔(如果QPS=100,则间隔是10毫秒)往桶里加入令牌,如果桶已经满了就不再加了。 新请求来临时,会各自拿走一块令牌,如果没有令牌可拿就阻塞或者拒绝服务。
常见的限流算法
1.计数器算法
计数器算法是使用计数器实现的限流算法,实现简单。 比如,限流策略为在1秒内只允许有100个请求通过,算法的实现思路是第一个请求进来时计数为1,后面每通过一个请求计数加1。 当计数满100后,后面的请求全部被拒绝。 这种技术算法非常简单,当流量突发时,它只允许前面的请求通过,一旦计数满了,拒绝所有后续请求,这种现象称为“突刺现象”。
2.漏桶算法
漏桶算法可以消除“突刺现象”,其内部有一个容器,类似漏斗,当请求进来时,相当于水倒入漏斗,然后从容器中均匀地取出请求进行处理,处理速率是固定的。 不管上面流量多大,都全部装进容器,下面流出的速率始终保持不变。 当容器中的请求数装满了,就直接拒绝请求。
3.令牌桶算法
令牌桶算法是对漏桶算法的改进,漏桶算法只能均匀地处理请求。 令牌桶算法能够在均匀处理请求的情况下,应对一定程度上的突发流量。 令牌桶算法需要一个容器来存储令牌,令牌以一定的速率均匀地向桶中存放,当超过桶的容量时,桶会丢弃多余的令牌。 当一个请求进来时,需要从令牌桶获取令牌,获取令牌成功,则请求通过;如果令牌桶中的令牌消耗完了,则获取令牌失败,拒绝请求。
Spring Cloud微服务快速上手-限流
限流是通过限制并发访问数,或者限制一个时间窗口内允许处理的请求数量来保护系统,一旦达到限制的请求数量(略小于提前对系统进行压力测试得到的峰值),就对请求采取拒绝策略,如跳转到排队页面、提醒用户系统繁忙等。 本质就是牺牲一部分用户的可用性,为大部分用户提供稳定的服务。
限流可以通过下面两种方式来实现。
- 在Nginx层添加限流模块来进行限制。
- 通过Guava提供的Ratelimiter来进行限制。
要实现限流,还需要对限流算法有所了解。这是面试中常考的问题,也是工作中常用的技术。
计数器(固定窗口)算法
计数器算法,是指在指定的时间周期内,累加访问的次数达到设定的阈值时,触发的限流策略。 在下一个时间周期进行访问时,访问次数清零。 此算法无论在单机还是分布式环境下实现都非常简单,使用Redis的incr原子自增性,再结合key的过期时间,即可轻松实现。
滑动时间窗口算法
为了解决计数器算法的临界值问题,开发了滑动窗口算法。在TCP网络通信协议中,就是采用滑动时间窗口算法来解决网络拥堵的问题。
滑动时间窗口是将计数器算法中的时间周期切分成多个小的时间窗口,分别在每个小的时间窗口中记录访问次数,然后根据时间将窗口往前滑动并删除过期的小时间窗口。 最终只需要统计滑动窗口范围内的小时间窗口的总的请求数即可。
在滑动时间窗口算法中,小窗口划分的越多,滑动窗口的滚动就越平滑,限流的统计就会越精确。
漏桶限流算法
漏桶限流算法的原理就像它的名字一样,维持一个漏斗,它有恒定的流出速度,不管水流流入的速度有多快,漏斗出水的速度始终保持不变,类似于消息中间件,不管消息的生产者请求量有多大,消息的处理能力取决于消费者。
漏桶的容量=漏桶的流出速度×可接受的等待时长。在这个容量范围内的请求可以排队等待系统的处理,超过这个容量的请求才会被抛弃。
在漏桶限流算法中,存在下面几种情况。
- 当请求速度大于漏桶的流出速度时,也就是请求量大于当前服务所能处理的最大极限值时,触发限流策略。
- 当请求速度小于或等于漏桶的流出速度时,也就是服务的处理能力大于或等于请求量时,正常执行。
漏桶算法有一个缺点,当系统在短时间内有突发的大流量时,漏桶算法就处理不了。
令牌桶限流算法
为了改进漏桶限流算法处理不了短期内的突发大流量的问题,引入了令牌桶限流算法。
令牌桶限流算法增加了一个大小固定的容器,也就是令牌桶,系统以恒定的速率向令牌桶中放入令牌,如果有客户端来请求,需要先从令牌桶中拿一个令牌,拿到了令牌才有资格访问系统,这时令牌桶中相应也少了一个令牌。当令牌桶满的时候,再向令牌桶生成令牌,令牌会被抛弃。
在令牌桶限流算法中,存在以下几种情况。
- 当请求速度大于令牌的生成速度时,令牌桶中的令牌会被取完,后续再进来的请求,由于拿不到令牌,会被限流。
- 当请求速度等于令牌的生成速度时,系统处于平稳状态。
- 当请求速度小于令牌的生成速度时,系统的访问量远远低于系统的并发能力,请求可以被正常处理。
令牌桶限流算法由于有一个桶的存在,所以可以处理短时间内大流量的场景。这是令牌桶限流和漏桶限流算法的一个区别。
微服务之道:度量驱动开发-限流——速率控制
- 它其实是一个消息队列系统。
- 它其实是一个事件驱动系统。
- 它其实就是一个排队机。
任何系统都有容量的限制,为了使服务保持高可用性,我们必须对系统进行限流,也称速率限制(rate limiting)。
限流和流量控制还有点区别,在传输层协议层面上就已经做了一些流量控制,TCP通过可变大小的滑动窗口来进行数据传输的流量控制。 简单来说,发送方有一个滑动窗口,大小为10,也就是说发送10字节之后才等待接收方的响应。 接收方在接收确认消息中包含一个窗口建议(window advertisement),告之发送方——作为接收方准备好接收多少字节的数据。 这个值如果比较大,那么发送方的滑动窗口可以增大,可以快点发送数据,因为接收方的处理效率很高;反之,则减小滑动窗口的大小,这样就减慢了发送速率。 当滑动窗口大小为1时,则发送每个消息都要等待确认消息收到后才发送下一个。
大多数消息队列系统也用到了限流,当生产者过快地发送消息,而消费者没法及时处理时,系统会返回一个异常消息,告诉生产者慢点生产。
而这里讲的限流是指速率控制。 服务器端对客户端的请求进行监控,当发觉某个客户端发送了过多或过快的请求时就会做出限制,根据预先制定的策略针对某个客户端的IP、账户或类型进行限流,从而保证对大多数正常请求的服务不受影响,防止拒绝服务DoS(Denial of Service)和分布式拒绝服务DDoS(Distributed Denial of Service)。 DoS是很常见的网络攻击方式,限流或者说速率控制(ratelimiting)是行之有效的应对手段。
限流可以是比较粗放的,只根据每秒请求数的阈值来进行控制,超过QPS/TPS上限的请求一律拒绝掉。 这种方式有效,但是不能精准打击那些攻击者,反而会误伤无辜。
类似用户层面的限流,一旦我们可以辨别出应用程序的标识,就可以针对特定应用程序的请求进行计数,按照下面介绍的限流算法来进行速率控制。
限流算法
漏桶(leaky bucket)
生活中常见的漏斗用于从油桶往油瓶里倒油,如果没有漏斗,除非是卖油翁那样的高手,多数情况下油都会跑冒滴漏。
漏桶是类似的东西。 海量请求扑面而来,可能瞬时就会把服务器压垮,而漏桶可以用来限流削峰。 漏桶的总容量是不变的,请求以任意速率流入,但总是以恒定速率流出。 如果请求来得太多太快,桶就会被盛满,后续的请求就会被拒绝。 也就是说当一个请求到来,就将这个请求放进桶里,如果可以放入,则处理此请求,否则漏桶已满,则拒绝此请求,直到桶中请求不再满时。
令牌桶(token bucket)
令牌桶与上面的漏桶异曲同工,只不过它不是以固定速率流出,而是以固定速率放入令牌到令牌桶中。 请求到来时从令牌桶中领取一个令牌才可继续处理服务,如果取不到令牌,则拒绝此请求。
固定窗口(fixed window)
固定窗口算法,也就是用一个固定的时间窗口来跟踪速率,每一个请求会增加这个窗口中的计数器,请求来了加1,处理完成就会减1。如果这个计数器超过了阈值,后续的请求就会被丢弃。
滑动日志(sliding log)
以时间戳为关键字将请求日志保存在一张表中,每个请求都会在这张表中添加一条日志,日志的生存周期(Time To Live,TTL)有限,过期的日志会被删除。 如果表中所存储的日志数已经达到了阈值,后续的新请求就会被丢弃。
滑动窗口(sliding window)
滑动窗口是一种改进算法,综合了固定窗口和滑动日志两种方法的优点。 它结合了固定窗口算法的低处理成本和滑动日志改进的边界条件,将当前时间窗口与过去时间窗口综合考虑。 与固定窗口算法一样,滑动窗口根据请求更改每个固定窗口的计数器。 接下来,再根据当前时间戳计算当前窗口的加权值,以及上一个窗口的请求率的加权值,以平滑突发流量。 例如,如果当前窗口是25%,那么我们将前一个窗口的计数加权75%。
限流级别
限流级别其实就是计数器涵盖的范围,通过实例级别也就够了,单个实例超过流量了,由于前面都有一个负载均衡器存在,其他实例很可能也会过载。
限流级别大致可以分为以下4级:
- 实例级别(instance)
- 服务器级别(server)
- 集群级别(pool/cluster)
- 数据中心(data center)
限流范围
具体到限流范围,可根据源地址、用户、应用程序,还可以加上微服务自身所提供的不同端点来划分。
- 全部端点(all endpoint)/特定端点(specified endpoint)
- 全部源地址/特定源地址
- 全部用户/特定用户
- 全部应用程序/特定应用程序
限流策略
最简单的策略当然是直接拒绝,简单有效。但是如果想做得比较平滑优雅,可以部分拒绝,逐步收窄。对于那些十分重要的大客户,在没有额外资源可以调度的情况下,甚至可以设置为永不拒绝策略。
- 全部拒绝:在指定时间间隔内拒绝所有的请求。
- 部分拒绝:在指定时间间隔内允许若干个请求,即指定下列指标的上限。
- ○每秒请求数QPS(Query Per Second)。
- ○每台机器的请求数QPM(Query Per Machine):指每个客户端发送的请求数。
- ○每个主机的请求数QPH(Query Per Host):指服务器端每台主机的请求数。
- 从不拒绝:对于某些非常重要的客户,总是允许他们的请求,直至系统资源耗尽。
限流度量及触发条件
根据上述算法,关键的度量指标就是计数器。
- 漏桶中的请求数是否已经达到阈值。
- 令牌桶中的令牌数是否已经领光。
- 固定窗口或滑动窗口中的计数器是否已经达到阈值。
- 滑动日志中所存储的日志数是否已经达到阈值。
当然,还可以设置更加细致的匹配和分组条件。例如:
- API端点信息,如url、responseCode、header、method、param。
- 用户信息,如userId、orgId。
- ip地址信息,如source_address、x-forwarded-for。
触发条件一般是单位时间内的最大请求数。例如:
- 单位时间内的请求数(request count per interval)
- 单位时间内的错误码次数(error code count per interval)
- 单位时间内的并发请求数(concurrent request per interval)
Sentinel 集群限流
由于请求倾斜的存在,分发到集群中每个节点上的流量不可能是均匀的,因此单机限流无法实现精确地限制整个集群的整体流量,从而造成在总流量没有达到阈值的情况下一些机器就开始限流。
例如,服务A部署了3个节点,规则配置限流阈值为200QPS,则在理想情况下集群的限流阈值为600QPS,若某个节点先达到200QPS,机器就会开始限流,而其他节点才达到100QPS,此时集群的QPS为400。
Sentinel 1.4.0开始引入集群限流功能,目的是实现精确地控制整个集群的QPS。
本章内容主要包括以下几个方面。
- 本地限流与集群限流。
- 集群限流的两种模式。
- 集群限流功能的实现。
本地限流与集群限流
在分析限流与热点参数限流源码的过程中,我们发现无论是限流的本地限流与集群限流,还是热点参数限流的本地限流与集群限流,它们的入口都相同,只是所走的can pass check逻辑不同。
单机限流的整个工作流程如下。
FlowSlot作为实现限流功能的入口,在entry方法中调用FlowRuleChecker#checkFlow方法判断是否需要限流。FlowRuleChecker根据资源名称从限流规则管理器中获取限流规则,并遍历限流规则。- 根据限流规则配置的
clusterMode决定走本地限流逻辑还是走集群限流逻辑。 - 如果走本地限流逻辑,则调用流量效果控制器判断是否拒绝当前请求。
集群限流是在第三步的基础上实现的,如果限流规则配置的clusterMode为集群限流模式,则向集群限流服务端发起远程调用,由集群限流服务端判断是否拒绝当前请求,且流量效果控制也是在集群限流服务端完成的。
限流的can pass check流程如图所示。
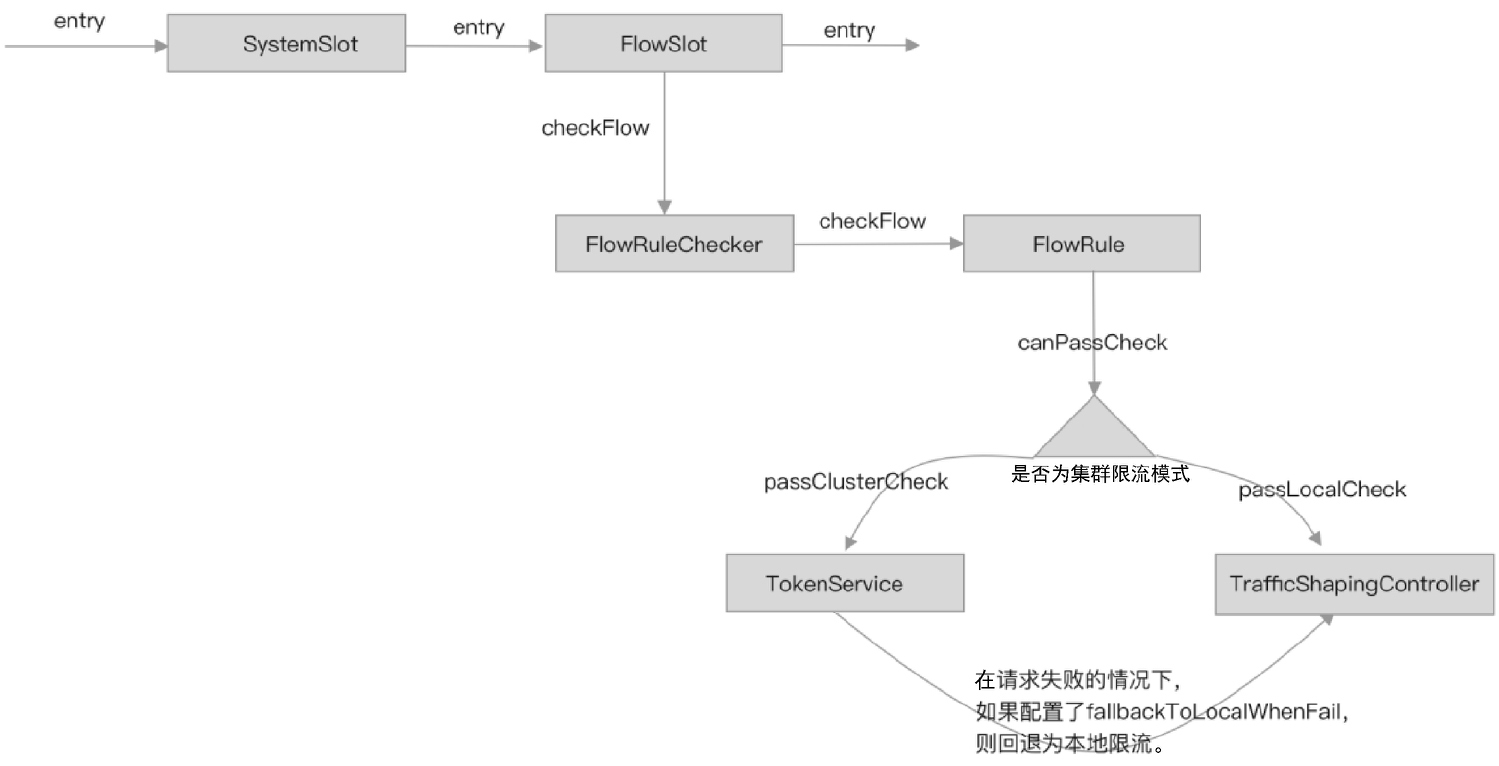
由图可知,当规则配置为集群限流模式时,集群限流客户端通过TokenService向集群限流服务端发起RPC远程调用;集群限流服务端根据响应结果决定如何控制当前请求。
集群限流的两种模式
Sentinel支持采用两种模式启动集群限流服务端,分别是嵌入式模式和独立应用模式。这两种模式都有各自的优缺点。
嵌入式模式
嵌入式模式是指将集群限流服务端作为应用的内置服务同应用一起启动,与应用在同一个进程,可动态地挑选其中一个节点作为集群限流服务端。嵌入式模式如图所示。
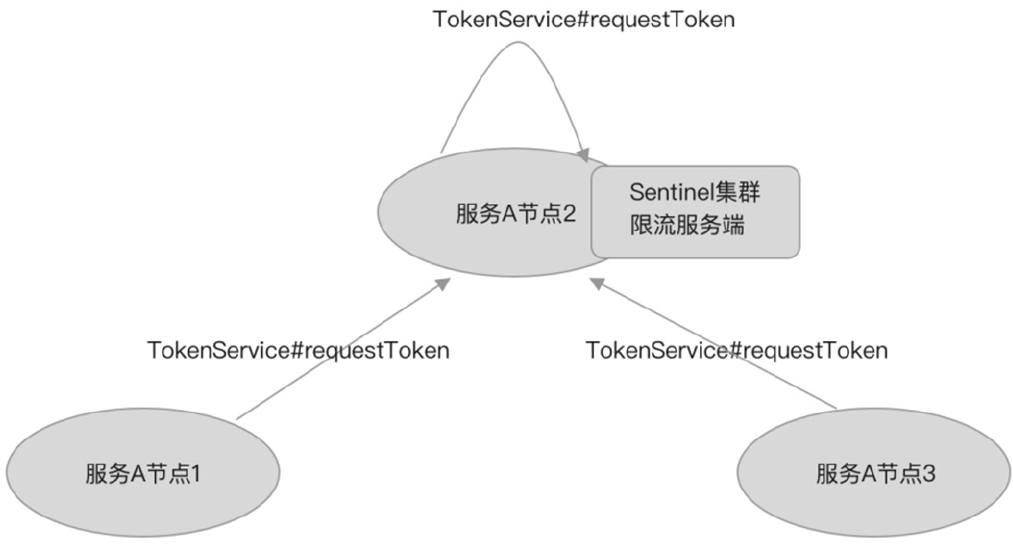
- 优点:无须单独部署,可动态切换集群限流服务端。
- 缺点:将集群限流服务端嵌入应用中,作为集群限流服务端的节点需要处理集群内的其他限流客户端发来的请求,会影响应用的性能。
- 适用场景:适用于单个微服务实现集群内部限流的场景,如只对服务A内部集群限流提供服务。
如果将服务部署在Kubernetes平台上,则嵌入式模式还有另外一个缺点。 由于POD的重启会造成POD动态IP地址变更,因此使用嵌入式模式需要频繁调整配置,以选择一个节点作为集群限流服务端,并且需要调整其他客户端的连接配置,才能让其他客户端连接上服务端。
试想一下,如果某个节点挂掉了,且该节点正好作为集群限流的服务端,由于配置不变,Kubernetes为了保持服务总存活的节点数就会新起一个POD,而新起的POD的IP地址与挂掉的POD的IP地址肯定不同,则新起的节点就变成了集群限流客户端,此时,所有集群限流客户端都会连接不上服务端,最终只能回退为本地限流。
独立应用模式
独立应用模式是指将集群限流服务端作为一个独立的应用部署,如图所示。
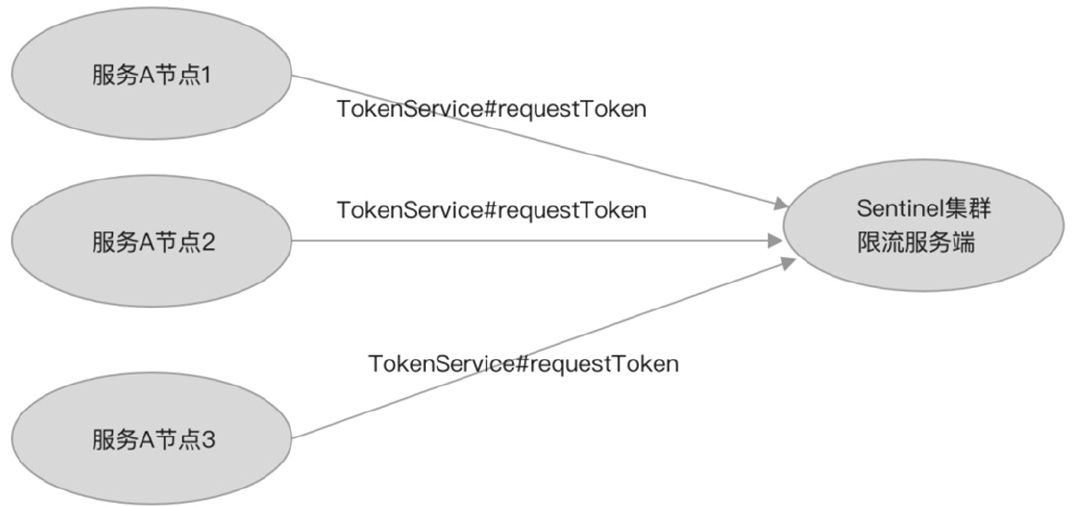
- 优点:与应用隔离,不影响应用的性能。
- 适用场景:适用于为所有微服务实现集群限流提供服务,如服务A和服务B等所有微服务都可以接入这个集群限流服务端。
Sentinel集群限流客户端与集群限流服务端通信只保持一个长连接,底层通信基于Netty框架实现,使用自定义通信协议,并且数据包设计得足够小,对网络I/O性能的影响可降到最低,再加上集群限流服务端处理一次requestToken请求都会访问内存且计算量少,响应时间短,因此使用集群限流功能对集群限流客户端性能的影响并不大。
Sentinel集群限流对集群限流服务端的可用性要求不高,当集群限流服务端挂掉时,可回退为本地限流。嵌入式模式并未实现类似于主/从自动切换的功能,当集群限流服务端挂掉时,集群限流客户端并不能自动切换为集群限流服务端。所以选择哪种集群限流服务端启动模式更多的是考虑使用嵌入式模式是否会严重影响应用的性能,以及应用是否有必要严重依赖集群限流。当然,如果服务是部署在Kubernetes平台上的,就应该选择独立应用模式。
集群限流功能的实现
Sentinel集群限流功能是基于令牌桶算法实现的。集群限流就是让集群限流服务端负责生产令牌,让集群限流客户端向集群限流服务端申请令牌,只有在集群限流客户端申请到令牌时才能放行请求,否则拒绝请求。
集群限流也支持热点参数限流,两者的实现原理大致相同,所以关于热点参数的集群限流将留给读者自己去研究。
sentinel-cluster包含以下几个重要模块。
sentinel-cluster-common-default:公共模块,定义通信协议,包括编码器和解码器接口、请求和响应实体(数据包),与底层使用哪种通信框架无关。sentinel-cluster-client-default:集群限流客户端模块,实现公共模块定义的接口,使用Netty进行通信,实现自动连接与掉线重连,提供连接配置API。sentinel-cluster-server-default:集群限流服务端模块,实现公共模块定义的接口,使用Netty进行通信,实现TokenService接口。
集群限流规则
集群限流规则即FlowRule,当FlowRule实例的clusterMode字段被配置为true时,表示这个规则是一个集群限流规则。
如果将一个限流规则配置为集群限流规则,则FlowRule实例的clusterConfig字段必须被配置,该字段的类型为ClusterFlowConfig。
ClusterFlowConfig类的源码如下。
public class ClusterFlowConfig {
private Long flowId;
private int thresholdType = ClusterRuleConstant.FLOW_THRESHOLD_AVG_LOCAL;
private boolean fallbackToLocalWhenFail = true;
// 当前版本未使用
private int strategy = ClusterRuleConstant.FLOW_CLUSTER_STRATEGY_NORMAL;
private int sampleCount = ClusterRuleConstant.DEFAULT_CLUSTER_SAMPLE_COUNT;
private int windowIntervalMs = RuleConstant.DEFAULT_WINDOW_INTERVAL_MS;
}
flowId:集群限流规则的全局唯一ID。thresholdType:集群限流阈值类型。fallbackToLocalWhenFail:失败时是否回退为本地限流模式,默认为true。sampleCount:滑动窗口构造方法的参数之一,指定WindowWrap的数组大小。windowIntervalMs:滑动窗口构造方法的参数之一,指定整个滑动窗口的周期(每个WindowWrap的时间窗口大小=windowIntervalMs/sampleCount)。
当限流规则配置为集群限流模式时,限流规则的阈值类型(grade)将被弃用,转而使用集群限流配置(ClusterFlowConfig)的阈值类型(thresholdType),支持单机均摊和集群总阈值两种集群限流阈值类型。
- 单机均摊类型:将当前连接到集群限流服务端的集群限流客户端节点数乘以规则配置的count的结果作为集群的QPS限流阈值。
- 集群总阈值类型:将规则配置的count作为集群的QPS限流阈值。
集群限流规则的动态配置
集群限流规则需要在集群限流客户端配置一份,同时需要在集群限流服务端也配置一份。集群限流客户端需要取得集群限流规则才会走集群限流模式,而集群限流服务端需要取得同样的集群限流规则才能正确地回应集群限流客户端。
为了统一规则配置,我们应当选择动态配置,让集群限流客户端和集群限流服务端从同一数据源中获取同一份数据。
Sentinel支持使用名称空间(namespace)区分不同应用之间的集群限流规则配置,如服务A的集群限流规则配置和服务B的集群限流规则配置可以使用名称空间隔离。
我们已经分析了Sentinel动态数据源的实现原理,并且基于Spring Cloud提供的动态配置功能实现了一个动态数据源。为了便于理解和测试,我们将自行实现一个简单的动态数据源(SimpleLocalDataSource),实现根据名称空间加载集群限流规则。
SimpleLocalDataSource类继承AbstractDataSource抽象类,同时SimpleLocalDataSource类的构造方法要求传入名称空间,用于指定一个SimpleLocalDataSource实例只负责加载指定名称空间的集群限流规则。SimpleLocalDataSource类的代码如下。
public class SimpleLocalDataSource extends AbstractDataSource<String, List<FlowRule>> implements Runnable {
public SimpleLocalDataSource(String namespace) {
super(new SimpleConverter<String, List<FlowRule>>());
// 模拟Spring容器刷新完成,初始化加载一次集群限流规则
new Thread(this).start();
}
@Override
public String readSource() throws Exception {
return "";
}
@Override
public void close() throws Exception {
}
@Override
public void run() {
try {
// 休眠6秒
Thread.sleep(6000);
getProperty().updateValue(loadConfig());
} catch (Exception e) {
e.printStackTrace();
}
}
}
我们在SimpleLocalDataSource类的构造方法中启动一个线程,用于实现等待动态数据源注册到ClusterFlowRuleManager之后模拟加载一次集群限流规则。
由于是测试,因此SimpleLocalDataSource类的readSource方法并未被实现,我们直接在SimpleConverter转换器中虚构一个集群限流规则,代码如下。
public class SimpleConverter extends Converter<String, List<FlowRule>>() {
@Override
public List<FlowRule> convert(String source) {
List<FlowRule> flowRules = new ArrayList<>();
FlowRule flowRule = new FlowRule();
flowRule.setCount(200);
flowRule.setResource("GET:/hello");
// 集群限流配置
flowRule.setClusterMode(true);
ClusterFlowConfig clusterFlowConfig = new ClusterFlowConfig();
clusterFlowConfig.setFlowId(10000L);
// ID确保全局唯一
flowRule.setClusterConfig(clusterFlowConfig);
flowRules.add(flowRule);
return flowRules;
}
}
接下来,我们将使用这个动态数据源实现集群限流客户端和集群限流服务端的配置。
集群限流客户端配置
在需要使用集群限流功能的微服务项目中添加sentinel-cluster-client-default模块的依赖,代码如下。
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-cluster-client-default</artifactId>
<version>${version}</version>
</dependency>
将身份设置为集群限流客户端(CLUSTER_CLIENT),并且将ClusterClientConfig实例注册到ClusterClientConfigManager中,代码如下。
@SpringBootApplication
public class WebMvcDemoApplication {
static {
// 指定当前身份为 Token Client
ClusterStateManager.applyState(ClusterStateManager.CLUSTER_CLIENT);
// 集群限流客户端配置,ClusterClientConfig目前只支持配置请求超时
ClusterClientConfig clientConfig = new ClusterClientConfig();
clientConfig.setRequestTimeout(1000);
ClusterClientConfigManager.applyNewConfig(clientConfig);
}
}
在Spring项目中,可通过监听ContextRefreshedEvent事件,在Spring容器启动完成后初始化创建动态数据源并为FlowRuleManager注册限流规则动态数据源,代码如下。
@SpringBootApplication
public class WebMvcDemoApplication implements ApplicationListener<ContextRefreshedEvent>{
@Override
public void onApplicationEvent(ContextRefreshedEvent contextRefreshedEvent) {
// 指定名称空间为serviceA,只加载这个名称空间下的限流规则
SimpleLocalDataSource ruleSource = new SimpleLocalDataSource("serviceA");
FlowRuleManager.register2Property(ruleSource.getProperty());
}
}
注册用于连接到集群限流服务端的配置(ClusterClientAssignConfig),指定集群限流服务端的IP地址和端口,代码如下。
@SpringBootApplication
public class WebMvcDemoApplication {
static {
ClusterClientAssignConfig assignConfig = new ClusterClientAssignConfig();
assignConfig.setServerHost("127.0.0.1");
assignConfig.setServerPort(11111);
// 指定名称空间为serviceA
ConfigSupplierRegistry.setNamespaceSupplier(()->"serviceA");
ClusterClientConfigManager.applyNewAssignConfig(assignConfig);
}
}
提示:当ClusterClientConfigManager#applyNewAssignConfig方法被调用时,会触发Sentinel初始化或重新连接到集群限流服务端,所以我们看不到启动集群限流客户端的代码。当集群限流客户端与集群限流服务端意外断开连接时,Sentinel还支持集群限流客户端不断地重试重连。
我们在调用ClusterClientConfigManager#applyNewAssignConfig方法之前,先调用了ConfigSupplierRegistry#setNamespaceSupplier方法注册名称空间,这是非常重要的一步。当集群限流客户端连接上集群限流服务端时,会立即发送一个PING类型的消息给集群限流服务端。Sentinel会将名称空间携带在PING数据包上传递给集群限流服务端,集群限流服务端以此获得每个集群限流客户端连接的名称空间。
在完成以上步骤后,集群限流客户端就已经配置完成,如果集群限流服务端使用嵌入式模式启动,则还需要在同一个项目中添加集群限流服务端的配置。
集群限流服务端配置
如果使用嵌入式模式,则可以直接在微服务项目中添加sentinel-cluster-server-default模块的依赖;如果使用独立应用模式,则需要单独创建一个项目,在独立项目中添加sentinel-cluster-server-default模块的依赖。
在项目的依赖配置文件中添加如下配置。
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-cluster-server-default</artifactId>
<version>${version}</version>
</dependency>
在独立应用模式下,需要手动创建ClusterTokenServer并启动,在启动之前需要指定监听端口和连接最大空闲等待时间等配置,代码如下。
public class ClusterServerDemo {
public static void main(String[] args) throws Exception {
ClusterTokenServer tokenServer = new SentinelDefaultTokenServer();
// 配置监听端口和连接最大空闲等待时间
ClusterServerConfigManager.loadGlobalTransportConfig(new ServerTransportConfig()
.setIdleSeconds(600)
.setPort(11111));
// 启动服务
tokenServer.start();
}
}
接下来需要为集群限流服务端创建用于加载集群限流规则的动态数据源,在创建动态数据源时,需要指定数据源只加载哪个名称空间下的限流规则配置,代码如下。
ClusterFlowRuleManager.setPropertySupplier(new Function<String, SentinelProperty<List<FlowRule>>>() {
// ClusterFlowRuleManager会给apply方法返回的SentinelProperty注册监听器
@Override
public SentinelProperty<List<FlowRule>> apply(String namespace) {
// 创建动态数据源
SimpleLocalDataSource source = new SimpleLocalDataSource(namespace);
// 返回动态数据源的SentinelProperty
return source.getProperty();
}
});
从代码中可以看出,我们注册的是一个Java8的Function,这个Function的apply方法将在注册名称空间时触发调用。
现在,我们为集群限流服务端注册名称空间以触发动态数据源的创建,使得ClusterFlowRuleManager拿到动态数据源的SentinelProperty,将规则缓存更新监听器注册到动态数据源的SentinelProperty上。注册名称空间的代码如下。
// 多个应用应该对应多个名称空间,应用之间通过名称空间互相隔离
ClusterServerConfigManager.loadServerNamespaceSet(Collections.singleton("serviceA"));
名称空间可以有多个,但是如果存在多个名称空间,则会多次调用ClusterFlowRuleManager#setPropertySupplier方法注册的Function对象的apply方法,从而创建多个动态数据源。
由于我们在SimpleLocalDataSource的构造方法中创建了一个线程并延迟执行,因此当以上步骤完成后,也就是当SimpleLocalDataSource的延时任务执行时,SimpleLocalDataSource会加载一次限流规则配置,并调用SentinelProperty#updateValue方法通知ClusterFlowRuleManager更新限流规则配置。
在实际项目中,自定义的动态数据源可以通过定时拉取方式从配置中心中拉取规则,也可以结合Spring Cloud动态配置使用,通过监听动态配置改变事件,获取最新的规则配置,而规则的初始化加载,可通过监听Spring容器刷新完成事件实现。
动态配置为嵌入式模式提供支持
如果采用嵌入式模式启动,则除非一开始就清楚地知道应用会部署多少个节点,这些节点的IP地址是什么,并且不会改变,否则无法使用静态配置的方式去指定某个节点的角色。Sentinel为此提供了支持动态改变某个节点角色的API,使用方式如下。
http://<节点ip>:<节点port>/setClusterMode?mode={state}
其中,{state}为0代表集群限流客户端,为1代表集群限流服务端。当一个新的节点被选为集群限流服务端后,旧的集群限流服务端节点应该变为集群限流客户端,并且其他的节点都需要做出改变以连接到这个新的集群限流服务端。
Sentinel提供动态修改ClusterClientAssignConfig和ClusterClientConfig的API,使用方式如下。
http://<节点ip>:<节点port>/cluster/client/modifyConfig?data={body}
其中,{body}要求是JSON格式的字符串,支持的参数配置如下。
- serverHost:集群限流服务端的IP地址。
- serverPort:集群限流服务端的端口。
- requestTimeout:请求的超时时间。
除了使用API可以动态修改节点角色、客户端连接到服务端的配置,Sentinel还支持通过动态配置方式修改,但无论使用哪种方式修改都有一个弊端:需要人工手动配置。
虽然未能实现自动切换,但不得不称赞的是,Sentinel将动态数据源与SentinelProperty结合使用,通过SentinelProperty实现的观察者模式,提供了更为灵活的嵌入式模式集群限流角色转换功能,支持以动态修改配置的方式重置嵌入式模式集群中任一节点的集群限流角色。
ClusterClientAssignConfig(客户端连接服务端配置)、ServerTransportConfig(服务端传输层配置,包括监听端口、连接最大空闲时间)、ClusterClientConfig(客户端配置,包括请求超时)、ClusterState(节点状态,包括集群限流客户端、集群限流服务端)都支持使用动态数据源方式配置。
- 当动态改变ClusterClientAssignConfig时,Sentinel将重新创建集群限流客户端与集群限流服务端的连接。
- 当动态改变ServerTransportConfig时,Sentinel将重启集群限流服务端。
- 对于嵌入式模式,当动态改变ClusterState时,如果改变前与改变后的状态不同,如从集群限流客户端角色变为集群限流服务端角色,则关闭集群限流客户端与集群限流服务端的连接,并且启动服务监听客户端连接,而其他节点也会监听到动态配置改变,重新连接到这个新的集群限流服务端。
集群限流核心类介绍
sentinel-core模块的cluster包中定义了实现集群限流功能的相关接口。
- TokenService:定义集群限流客户端向集群限流服务端申请Token的接口,由FlowRuleChecker调用。
- ClusterTokenClient:集群限流客户端需要实现的接口,继承TokenService。
- ClusterTokenServer:集群限流服务端需要实现的接口。
- EmbeddedClusterTokenServer:支持嵌入式模式的集群限流服务端需要实现的接口,继承TokenService和ClusterTokenServer。
TokenService是集群限流客户端与集群限流服务端通信的RPC接口,TokenService接口的定义如下。
public interface TokenService {
TokenResult requestToken(Long ruleId, int acquireCount, boolean prioritized);
TokenResult requestParamToken(Long ruleId, int acquireCount, Collection<Object>params);
}
- requestToken:向server申请令牌,参数1为集群限流规则ID,参数2为申请的令牌数,参数3为请求优先级。
- requestParamToken:用于支持热点参数集群限流向server申请令牌,参数1为集群限流规则ID,参数2为申请的令牌数,参数3为限流参数。
TokenResult实体类的定义如下。
public class TokenResult {
private Integer status;
private int remaining;
private int waitInMs;
private Map<String, String> attachments;
}
- status:请求的响应状态码。
- remaining:当前时间窗口剩余的令牌数。
- waitInMs:休眠等待时间,单位为毫秒,用于通知集群限流客户端当前请求可以放行,但需要先休眠指定时间后才能放行。
- attachments:附带的属性,暂未使用。
ClusterTokenClient是由集群限流客户端实现的接口,定义如下。
public interface ClusterTokenClient extends TokenService {
void start() throws Exception;
void stop() throws Exception;
}
ClusterTokenClient接口定义了启动和停止集群限流客户端的方法,负责维护集群限流客户端与集群限流服务端的连接。该接口还继承了TokenService,要求实现类必须实现requestToken方法和requestParamToken方法,向远程服务端请求获取令牌。
ClusterTokenServer是由集群限流服务端实现的接口,定义如下。
public interface EmbeddedClusterTokenServerextends ClusterTokenServer, TokenService {}
EmbeddedClusterTokenServer接口继承了ClusterTokenServer接口和TokenService接口,即整合了集群限流客户端和集群限流服务端的功能,为嵌入式模式提供支持。在嵌入式模式下,如果当前节点是集群限流服务端,就没有必要发起网络请求。
TokenService接口、ClusterTokenClient接口、ClusterTokenServer接口和EmbeddedClusterTokenServer接口及默认实现类的关系如图所示。
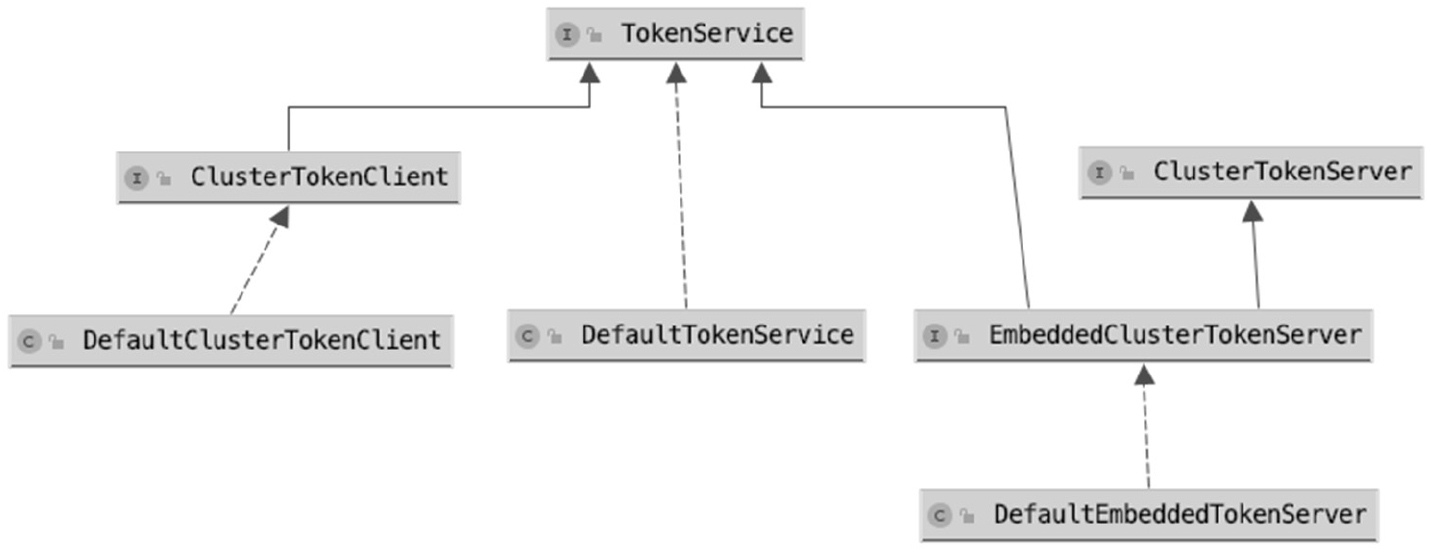
其中,DefaultClusterTokenClient是sentinel-cluster-client-default模块中的ClusterTokenClient接口的实现类,DefaultTokenService与DefaultEmbeddedTokenServer分别是sentinel-cluster-server-default模块中的ClusterTokenServer接口与EmbeddedClusterTokenServer接口的实现类。
当使用嵌入式模式启用集群限流服务端时,使用的TokenService实现类是DefaultEmbeddedTokenServer,而当使用独立应用模式启用集群限流服务端时,使用的TokenService实现类是DefaultTokenService。
集群限流客户端的实现
下面继续依据单机限流工作流程分析集群限流功能的实现,且从FlowRuleChecker# passClusterCheck方法开始。该方法的源码如下。
private static boolean passClusterCheck(FlowRule rule, Context context, DefaultNodenode, int acquireCount,boolean prioritized) {
try {
// ①
TokenService clusterService = pickClusterService();
if (clusterService == null) {
return fallbackToLocalOrPass(rule, context, node, acquireCount, prioritized);
}
// ②
long flowId = rule.getClusterConfig().getFlowId();
// ③
TokenResult result = clusterService.requestToken(flowId, acquireCount, prioritized);
return applyTokenResult(result, rule, context, node, acquireCount, prioritized);
} catch (Throwable ex) {
RecordLog.warn("[FlowRuleChecker] Request cluster token unexpected failed", ex);
}
// ④
return fallbackToLocalOrPass(rule, context, node, acquireCount, prioritized);
}
- ① 获取TokenService实例。
- ② 获取集群限流规则的全局唯一ID。
- ③ 调用TokenService#requestToken方法申请令牌。
- ④ 调用applyTokenResult方法处理响应结果。
pickClusterService方法可根据节点当前角色获取TokenService实例。 如果当前节点是集群限流客户端角色,则获取的TokenService实例类型为ClusterTokenClient,如果当前节点是集群限流服务端角色(嵌入式模式),则获取的TokenService实例类型为EmbeddedClusterTokenServer。 pickClusterService方法代码如下。
private static TokenService pickClusterService() {
// 集群限流客户端角色
if (ClusterStateManager.isClient()) {
return TokenClientProvider.getClient();
}
// 集群限流服务端角色(嵌入式模式)
if (ClusterStateManager.isServer()) {
return EmbeddedClusterTokenServerProvider.getServer();
}
return null;
}
ClusterTokenClient接口和EmbeddedClusterTokenServer接口都继承了TokenService接口,区别在于,ClusterTokenClient接口的实现类是通过向集群限流服务端发起请求来实现requestToken方法的,而EmbeddedClusterTokenServer接口的实现类在实现requestToken方法时不需要发起远程调用,因为在嵌入式模式下,如果当前节点角色是集群限流服务端,则调用的远程服务就是其自身。
在获取TokenService实例后,调用TokenService实例的requestToken方法请求获取Token。如果当前节点角色是集群限流客户端,则这一步骤会先将方法参数构造为请求数据包,再向集群限流服务端发起请求,并同步等待获取集群限流服务端的响应结果。因为网络通信的内容不在本书的讲解范围内,所以这里并没有展开分析。
applyTokenResult方法的源码如下。
private static boolean applyTokenResult(/*@NonNull*/ TokenResult result, FlowRulerule, Context context,DefaultNode node,int acquireCount, boolean prioritized) {
switch (result.getStatus()) {
case TokenResultStatus.OK:
return true;
case TokenResultStatus.SHOULD_WAIT:
try {
Thread.sleep(result.getWaitInMs());
} catch (InterruptedException e) {
}
return true;
case TokenResultStatus.NO_RULE_EXISTS:
case TokenResultStatus.BAD_REQUEST:
case TokenResultStatus.FAIL:
case TokenResultStatus.TOO_MANY_REQUEST:
return fallbackToLocalOrPass(rule, context, node, acquireCount, prioritized);
case TokenResultStatus.BLOCKED:
default:
return false;
}
}
applyTokenResult方法根据响应状态码决定是否拒绝当前请求。
- 当响应状态码为OK时,放行请求。
- 当响应状态码为SHOULD_WAIT时,休眠指定时间再放行请求。
- 当响应状态码为BLOCKED时,直接拒绝请求。
- 其他状态码均代表调用失败,根据规则配置的fallbackToLocalWhenFail是否为true决定是否回退为本地限流,如果需要回退为本地限流,则调用passLocalCheck方法重新判断。
在请求异常或集群限流服务端响应异常的情况下,都会调用fallbackToLocalOrPass方法。该方法的源码如下。
private static boolean fallbackToLocalOrPass(FlowRule rule, Context context, DefaultNode node, int acquireCount, boolean prioritized) {
if (rule.getClusterConfig().isFallbackToLocalWhenFail()) {
return passLocalCheck(rule, context, node, acquireCount, prioritized);
} else {
// The rule won't be activated, just pass.
return true;
}
}
fallbackToLocalOrPass方法根据规则配置的fallbackToLocalWhenFail决定是否回退为本地限流。如果将fallbackToLocalWhenFail配置为false,则会导致集群限流客户端在与集群限流服务端失联的情况下拒绝所有流量。fallbackToLocalWhenFail的默认值为true,建议不要将其修改为false,我们应当先确保服务的可用性,再确保集群限流的准确性。
由于网络延迟的存在,Sentinel集群限流并未实现匀速排队流量效果控制,也没有支持冷启动,而只支持直接拒绝请求的流量效果控制。响应状态码SHOULD_WAIT并非用于实现匀速限流,而是用于实现具有优先级的请求在达到限流阈值的情况下,可试着抢占下一个时间窗口的Token,如果抢占成功,则通知集群限流客户端,当前请求需要休眠等待下一个时间窗口的到来才可以放行。Sentinel使用“提前申请在未来时间通过”的方式实现优先级语意。
集群限流服务端的实现
无论是集群限流服务端接收集群限流客户端发来的requestToken请求,还是在嵌入式模式下自己向自己发起请求,最终都会交给DefaultTokenService处理。DefaultTokenService类实现的requestToken方法的源码如下。
@Override
public TokenResult requestToken(Long ruleId, int acquireCount, boolean prioritized){
// 验证规则是否存在
if (notValidRequest(ruleId, acquireCount)) {
return badRequest();
}
// ①
FlowRule rule = ClusterFlowRuleManager.getFlowRuleById(ruleId);
if (rule == null) {
return new TokenResult(TokenResultStatus.NO_RULE_EXISTS);
}
// ②
return ClusterFlowChecker.acquireClusterToken(rule, acquireCount, prioritized);
}
- ① 根据限流规则ID获取限流规则。
- ② 调用ClusterFlowChecker#acquireClusterToken方法继续处理请求。
提示:Sentinel只使用一个ID字段向集群限流服务端传递限流规则,减小了数据包的大小,优化了网络通信的性能。
由于ClusterFlowChecker#acquireClusterToken方法的源码太多,因此将acquireClusterToken方法拆分为4个部分进行分析。
第一部分的代码如下。
static TokenResult acquireClusterToken(FlowRule rule, int acquireCount, boolean prioritized) {
Long id = rule.getClusterConfig().getFlowId();
// 根据全局QPS阈值限流,按名称空间统计QPS
if (!allowProceed(id)) {
return new TokenResult(TokenResultStatus.TOO_MANY_REQUEST);
}
// 根据规则ID获取统计实时指标数据的滑动窗口,如果不存在,则响应FAIL状态码
ClusterMetric metric = ClusterMetricStatistics.getMetric(id);
if (metric == null) {
return new TokenResult(TokenResultStatus.FAIL);
}
// 计算每秒平均被放行请求数、集群限流阈值和剩余可用令牌数
double latestQps = metric.getAvg(ClusterFlowEvent.PASS);
double globalThreshold = calcGlobalThreshold(rule) * ClusterServerConfigManager.getExceedCount();
double nextRemaining = globalThreshold - latestQps - acquireCount;
if (nextRemaining >= 0) {
// 第二部分的代码
} else {
if (prioritized) {
// 第三部分的代码
}
// 第四部分的代码
}
}
计算集群限流阈值需要根据规则配置的阈值类型计算。calcGlobalThreshold方法的源码如下。
private static double calcGlobalThreshold(FlowRule rule) {
double count = rule.getCount();
switch (rule.getClusterConfig().getThresholdType()) {
case ClusterRuleConstant.FLOW_THRESHOLD_GLOBAL:
return count;
case ClusterRuleConstant.FLOW_THRESHOLD_AVG_LOCAL:
default:
int connectedCount = ClusterFlowRuleManager.getConnectedCount(rule.getClusterConfig().getFlowId());
return count * connectedCount;
}
}
- 当阈值类型为集群总阈值时,直接使用限流规则的阈值(count)。
- 当阈值类型为单机均摊时,根据规则ID获取当前连接的客户端总数,将当前连接的客户端总数乘以限流规则的阈值(count)的结果作为集群的QPS限流阈值。
这正是集群限流客户端在连接上集群限流服务端时,发送PING类型消息给集群限流服务端并将名称空间携带在PING数据包上传递给集群限流服务端的原因。当限流规则阈值类型为单机均摊时,需要知道哪些连接与限流规则所属名称空间相同,如果集群限流客户端不将名称空间传递给集群限流服务端,则计算出来的集群的QPS限流阈值将为0,导致所有请求都会被限流。这是我们在使用集群限流功能时特别需要注意的。
集群限流阈值根据规则配置的阈值和阈值类型计算得到,每秒平均被放行请求数可从滑动窗口中获取,而剩余可用令牌数(nextRemaining)等于集群的QPS限流阈值减去当前时间窗口已经放行的请求数,再减去当前请求预占用的acquireCount(一般情况下,acquireCount值为1)。
第二部分的代码如下。
metric.add(ClusterFlowEvent.PASS, acquireCount);
metric.add(ClusterFlowEvent.PASS_REQUEST, 1);
if (prioritized) {
metric.add(ClusterFlowEvent.OCCUPIED_PASS, acquireCount);
}
return new TokenResult(TokenResultStatus.OK).setRemaining((int) nextRemaining).setWaitInMs(0);
当nextRemaining的计算结果大于或等于0时,执行这部分代码,先统计放行指标数据,再将响应状态码OK发送给集群限流客户端。
第三部分的代码如下。
double occupyAvg = metric.getAvg(ClusterFlowEvent.WAITING);
if (occupyAvg <= ClusterServerConfigManager.getMaxOccupyRatio() * globalThreshold) {
int waitInMs = metric.tryOccupyNext(ClusterFlowEvent.PASS, acquireCount, globalThreshold);
if (waitInMs > 0) {
return new TokenResult(TokenResultStatus.SHOULD_WAIT).setRemaining(0).setWaitInMs(waitInMs);
}
}
当nextRemaining的计算结果小于0时,如果当前请求具有优先级,则执行这部分代码。计算是否允许抢占下一个时间窗口的Token,若允许,则通知集群限流客户端,当前请求可放行,但需要等待waitInMs(一个窗口时间大小)毫秒之后才可放行。
如果请求抢占到下一个时间窗口的Token,则下一个时间窗口的被放行请求数也需要加上这些提前占用Token的请求数,这将会影响下一个时间窗口可用的Token总数。
第四部分的代码如下。
metric.add(ClusterFlowEvent.BLOCK, acquireCount);
metric.add(ClusterFlowEvent.BLOCK_REQUEST, 1);
if (prioritized) {
metric.add(ClusterFlowEvent.OCCUPIED_BLOCK, acquireCount);
}
return blockedResult();
当nextRemaining的计算结果大于0且无优先级权限时,直接拒绝请求,统计拒绝指标数据。
集群限流指标数据统计的实现
集群限流使用的滑动窗口并非sentinel-core模块实现的滑动窗口,而是sentinel-cluster-server-default模块自己实现的滑动窗口。
ClusterFlowConfig的sampleCount与windowIntervalMs这两个配置项用于为集群限流规则创建统计指标数据的滑动窗口,并在加载集群限流规则时创建,源码如下。
private static void applyClusterFlowRule(List<FlowRule> list, /*@Valid*/ String namespace) {
...
for (FlowRule rule : list) {
if (!rule.isClusterMode()) {
continue;
}
...
ClusterFlowConfig clusterConfig = rule.getClusterConfig();
...
// 如果不存在,则为规则创建ClusterMetric,用于统计指标数据
ClusterMetricStatistics.putMetricIfAbsent(flowId, new ClusterMetric(clusterConfig.getSampleCount(), clusterConfig.getWindowIntervalMs()));
}
// 移除不再使用的 ClusterMetric
clearAndResetRulesConditional(namespace, new Predicate<Long>() {
@Override
public boolean test(Long flowId) {
return !ruleMap.containsKey(flowId);
}
});
FLOW_RULES.putAll(ruleMap);
NAMESPACE_FLOW_ID_MAP.put(namespace, flowIdSet);
}
实现集群限流需要收集的指标数据有以下几种。
public enum ClusterFlowEvent {
PASS,
BLOCK,
PASS_REQUEST,
BLOCK_REQUEST,
OCCUPIED_PASS,
OCCUPIED_BLOCK,
WAITING
}
- PASS:已经发放的令牌总数。
- BLOCK:令牌申请被驳回的总数。
- PASS_REQUEST:被放行的请求总数。
- BLOCK_REQUEST:被拒绝的请求总数。
- OCCUPIED_PASS:被上一个时间窗口抢占的令牌总数。
- OCCUPIED_BLOCK:上一个时间窗口抢占令牌失败的总数。
- WAITING:当前等待下一个时间窗口到来的请求总数。
除统计的指标项与在sentinel-core模块下实现的滑动窗口统计的指标项有些区别外,滑动窗口的实现方式都一致。
小结
集群限流服务端允许被嵌入应用服务中启动,也可以作为独立应用服务启动。嵌入式模式适用于单个微服务实现集群内部限流的场景,独立应用模式适用于多个微服务应用共享同一个集群限流服务端的场景。另外,独立应用模式不会影响应用性能,而嵌入式模式对应用性能会有所影响。
集群限流客户端需要指定名称空间,默认使用main方法所在类的全类名作为名称空间。在集群限流客户端连接到集群限流服务端时,集群限流客户端会立即向集群限流服务端发送一条PING消息,并将名称空间携带在PING数据包上传递给集群限流服务端。
集群限流规则的阈值支持单机均摊和集群总阈值两种类型,如果是单机均摊阈值类型,则集群限流服务端需要根据限流规则的名称空间获取该名称空间当前所有的客户端连接,并将当前连接的客户端总数乘以限流规则的阈值的结果作为集群的QPS限流阈值。
集群限流支持按名称空间全局限流,并且无视该名称空间下配置的任何限流规则,只要是同一名称空间的集群限流客户端发来的requestToken请求,都先按名称空间阈值过滤。但其并没有特别实用的场景,因此官方文档也并未介绍此特性。
建议按应用区分名称空间,而不是对整个项目的所有微服务项目都使用同一个名称空间,因为在限流规则阈值类型为单机均摊的情况下,将获取与限流规则所属名称空间相同的客户端连接数作为客户端总数,如果不是同一个应用,则会导致获取的客户端总数是整个项目所有微服务应用集群的客户端总数,限流就会出问题。
集群限流并不能完全解决请求倾斜问题,在请求倾斜严重的情况下,集群限流可能会导致某些节点的流量过高,从而导致系统的负载过高,这时就需要使用系统自适应限流和熔断降级作为兜底解决方案。
- Go语言编程之旅-接口限流控制
- 实现支持分布式的限流器。本章实现的限流器是基于本地计数器来做的,如果在分布式环境下,则可能会出现问题。假设需求是对全部后端服务的某个路由限流,这时使用本地计算器就会有问题,因为它只会单独对每一个Go进程进行累加计算。为了解决这个问题,请利用Redis实现TokenBucket,让其成为一个支持分布式的限流器。
- Guava之RateLimiter详解
- Spring微服务实战(第2版)-实现限流器模式
- 分布式系统架构与开发:技术原理与面试题解析-Hystrix熔断机制
- ⭐️凤凰架构:构建可靠的大型分布式系统-限流设计模式
- ⭐️未来架构:从服务化到云原生-限流
- ⭐️分布式架构原理与实践-集群限流
- ⭐️Spring Boot从入门到实战-限流
- ⭐️分布式高可用架构之道-限流
- 使用Sentinel实现限流控制
- Spring Cloud微服务和分布式系统实践
- 亿级流量网站架构核心技术-限流详解
- 实战Alibaba Sentinel:深度解析微服务高并发流量治理